浅谈Java垃圾回收与JVM
简介Java与JVM
- 为什么要有JVM。在程序里,没有一件事情是抽象出来一层解决不了的,如果有那就抽象出两层。
大家都知道,Java是一门跨平台的语言,有那么一个非常经典梗—一次编写,处处异常(一次编写,处处运行)。java是通过JVM实现在不同平台上运行的,无论你是Windows,Linux还是其他什么系统,只要你能装上对应的支持JVM,就可以把代码拿过来直接使用。不需要做任何修改(当你没有自定义或者调用一些特有的Native方法就可以)就可以直接运行。这就归功于JVM的设计,也就是Machine和Code之间抽象Virtual Machine(有所问题都可以通过抽象一个层次来解决);java不用与系统底层直接打交道,而是通过JVM进行内存的分配与回收,多线程的处理等等。
我们都知道高级语言一般分两种,一种是编译型语言,一种是解释型语言。编译型语言就是常用的C、C++,Basic等他们都是编译语言,使用的时候都是先编译成目标文件(也就是.o和.obj文件),然后再去链接相应的类库,的工具库,然后才能运行,(做了一大桌子菜,都做好了,才能开始吃饭;菜就是代码,人就是CPU;也就是代码在运行之前就已经确定了,不能在改变)。他们编译之后都变成了机器码,不同的机器上对机器码(就是CPU执行的指令,就是一大堆0和1)的要求可能也不同,比如32位机和64位机,windows系统和linux系统,所以可能在别的机器上完美运行的代码在其他机器上就会有问题。所以编译型语言在不同的平台上使用不同的编译器重新编译一遍才能运行而解释型语言就不一样,他是通过解释器,解释给系统底层,一般没有编译的过程,在运行时候解释给操作系统(这个过程就像吃火锅,你需要什么就在里面加什么根据自己的喜好,而且还可以在这个过程中在进行二次处理,比如说反射的一些应用。也就是程序会在运行时被解释。我们可以在解释之前做一些操作);这类语言有PHP,JavaScript,Ruby等等一般他们都是不需要编译。而java是介于这两者之间的一种语言。属于混合型。因为java有编译的过程(前期编译,后期编译),大多数时候java是被编译成字节码文件也就是.class文件。但是有一些常用或者热点代码也会直接编译成本地代码(机器码)直接被使用(详情可以看看JIT)。所以java属于混合型,这类型的语言还有C#。他们不是直接把代码交给解释器直接去执行,而是先编译成一个中间文件,然后再把中间文件交给解释器去处理。
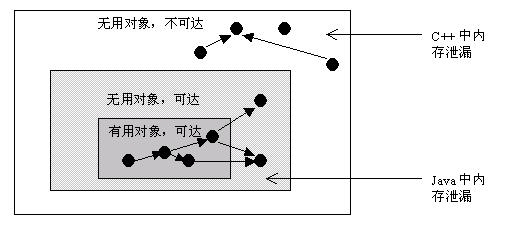
Java与C++之间有一堵内存动态分配和垃圾回收的技术所围城的“高墙”,墙外的人想进去,墙里的人却想出来。对与C和C++的程序员他们都是自己去管理内存(malloc和free)否则就会产生内存泄漏和溢出的问题。内存泄漏指的是本应该回收(不再使用)的内存对象无法被系统回收的现象;在C++和C中都是程序猿手动申请和释放,而java是通过JVM实现内存的分配和回收,可以减少内存的泄漏,但是也不能完全避免。java使用的是可达性算法,来回收那些没有使用的也就是不可达的对象。但是被使用对象引用的无用对象却不能被回收;内存泄漏一般都是情况有,单例模式的使用,类里面的静态变量,Threadlocal弱引用key问题等等;内存溢出是指当对象分配内存时,可用内存小于对象的内存,也就是内存不足现象。两者也是有一定关联也就是如果内存经常泄漏导致可用内存越来越少,最后会导致内存溢出。 同样内存溢出也可能会导致安全问题,一般是缓冲区和栈内存,因为他们都是连续的内存,所以黑客可以通过你内存的溢出的位置去查找你栈中和缓存区的数据,然后修改数据。不过程序猿把控制权交给了JVM,一旦出现内存泄漏和内存溢出问题就会很难排查。我之前有一篇文章写java内存模型的,可以先了解一下JVM内存。
JVM内存分配策略
- JAVA虚拟机里面各个区域都装的什么,难道是shit吗?
回顾
java运行时内存是由,java堆,虚拟机栈,程序计数器,方法区(现在是metadata),本地方法栈和运行常量池组成。还有一部分是直接内存,直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是java虚拟机规范中定义的内存区域,就是JVM以外的机器内存,比如,你有4G的内存,JVM占用了1G,则其余的3G就是直接内存。这部分被频繁的使用,所以也会出现OutOfMemory异常。在Java NIO中引入基于通道和缓冲区(Buffer)的I/O方式,它可以使用Native函数直接分配堆外内存也就是直接内存,(也就是JVM调用系统方法,把数据读取到内存中,而这一块内存不在JVM的堆内存中heap Memory。JVM在操作系统里其实就是一个进程)然后通过一个存储在java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些情况下显著提高性能,因为避免了在java堆和Native堆中来回的复制。
对象与引用
什么是对象(对象是程序运行时的实体;它的状态存储在 fields (也就是变量)行为是通过方法 (method) 实现的;方法上操作对象的内部的状态方法是对象对对象的通信的主要手段)。
肯定有人说对象就是女朋友啊。没错如果你没对象可以尝试new一个出来。放心你在怎么new都不会有对象(女朋友)。开个玩笑,对象就是程序运行时用来存储数据的一个集合体(实体),他包含你声明类(class)中有的变量(可能这些变量都是空)和一些操作变量的方法,一般java都是通过方法来操作属性,大多树情况下对象存在java堆中(也有可能存在堆上,这个要进行逃逸分析),通过引用去找到这个对象对象是程序运行时的实体。java是一门面向对象语言(Object-oriented programming OOP)。面向对象语言是对以前C的面向过程进行封装,过程都是通过函数来实现,也就是一个程序有很多函数。但是对象把函数和变量封装成一个整体,通过操作对象来实现对业务的处理(对数据的加工)或者实现功能,也可以说对象是对函数和变量的抽象。增加了代码的可复用性和灵活性,但是也增加了对象之间的关系比如说继承和多态(设计模式,增加代码的的复用性的设计)。其实函数式编程可以更好的减少代码(一个功能,代码写的越多bug越多,维护成本越高,尽量少写bug)。
什么是引用。(引用是数据存储于内存或存储设备中的地址。因此,引用亦常被称为该数据的指针或地址)
引用类型和其他基本类型差不多,都是存储值,只不过引用存储的是java堆内的地址。如果赋值了就像这样:
1 | Student s = new Student(); //创建一个新的Student对象 |
也就是把new 出来的 Student对象在java堆中的地址给s。之后我们操作这个新对象,都通过引用s。因为s就像一把钥匙能打开这个java堆中存储这个对象的大门,它可以操作Student对象的方法和变量,大多数时候我们都是这样操作对象。同样引用和基本类型都在栈上存储。但是String这个类型比较特殊,他的值一般都在堆上存储(直接赋值的String 一般都是存在字符串常量池( Strings Pool)在堆里,这样方便管理字符串内容相同的String对象,他们都指向一个字符串,而不是多个。new出来的String对象除外,不在池子里),这个和引用类型很类似,它也只存一个堆上的地址,所以这些类型在初始化时候为null,而其他类型会报错,同时String可以new出来。
1 | String s=null; //这样不会报错。 |
强引用,软引用,弱引用,虚引用,ReferenceQueue。
在JDK1.2以后,java对引用的概念进行的扩充,将引用分为强引用(Strong Reference),软引用(Soft Reference),弱引用(Weak Reference),虚引用(Phantom Reference)。这四种,引用强度分别减弱。肯定有人会问搞这么多东西干嘛,一种难道不够用吗。这些引用为垃圾回收提供了灵活的方式,我知道JVM垃圾回收不是通过引用技术的方式,而是通过可达性算法来实现,也就是这个对象有没有被引用。就会被定义为垃圾然后把他回收掉,但是有虚引用和弱引用,就可以在回收的时候不用计算一遍,减少Stop-The-World的时间,可以直接判断为垃圾或者回收掉。
强引用:强引用就是代码中普遍存在的引用例如Object obj=new Object(); 这类的引用。这里的obj是强引用。只要强引用还存在,垃圾回收器就不会回收该对象。当obj=null;的时候强引用的值消失,也就是该对象不可达。没有任何引用和可以操作该对象,表示该引用可以被回收。有时候强引用会显得“过强”,比如实现一个图像缓存,缓存中保存了对图像的引用,当图像不再使用时,如果缓存中还保存了对该图像的强引用,图像就不会被垃圾回收,需要手动断开缓存中的引用。
软引用:用来描述一些还有用但是非必需的对象。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象。因此,这一点可以很好地用来解决OOM的问题,并且这个特性很适合用来实现缓存:比如网页缓存、图片缓存等。
弱引用:弱引用来描述非必需的对象,他的强度比软引用还要低。被弱引用关联的对象会在下一次GC的时候回收掉,无论当前内存是否充足,他的生命周期就是一个GC周期。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。弱引用对象的存在不会阻止它所指向的对象变被垃圾回收器回收。弱引用最常见的用途是实现规范映射(canonicalizing mappings,比如哈希表(WeakHashMap)。假设垃圾收集器在某个时间点决定一个对象是弱可达的(weakly reachable)(也就是说当前指向它的全都是弱引用),这时垃圾收集器会清除所有指向该对象的弱引用,然后垃圾收集器会把这个弱可达对象标记为可终结(finalizable)的,这样它们随后就会被回收。与此同时或稍后,垃圾收集器会把那些刚清除的弱引用放入创建弱引用对象时所登记到的引用队列(Reference Queue)中。
虚引用:又称为幽灵引用或幻影引用,虚引用既不会影响对象的生命周期,也无法通过虚引用来获取对象实例,仅用于在发生GC时接收一个系统通知。无法通过虚引用来获取对象。虚引用只能和ReferenceQueue一起使用。
虚引用:一个对象是都有虚引用的存在都不会对生存时间都构成影响,也无法通过虚引用来获取对一个对象的真实引用。唯一的用处:能在对象被GC时收到系统通知,JAVA中用PhantomReference来实现虚引用。PhantomReferenc的get()始终返回null,无法通过虚引用来获取对象。虚引用只能和ReferenceQueue一起使用。
ReferenceQueue:翻译过来就是引用队列。垃圾回收器可以在对象的可及性发生特定的改变时,把对象的引用加入到ReferenceQueue,可以记录被回收对象的引用。如果在WeakReference的构造器中指定一个ReferenceQueue,那么当该WeakReference(弱引用也包含软引用)指向的对象变为垃圾时,该对象就会被自动加入到所指定ReferenceQueue中,之后就可以通过这个ReferenceQueue来为死引用(Dead Reference)进行清理工作。
java各个分区内存储的内容
我之前的博客有写可以去看一下java运行时内存模型,里面大致的讲了一下上面说的那5个区域都存的什么,不过JDK8版本后,把方法区改成了MetaData区(元数据区)一般MetaData和Native都属于非堆内存。堆内存指的是Survivor0,Survivor1,Eden,Old总和。在一点就是Java中不是所有的对象都会分配在堆上的,也有对象被分配到栈上。
逃逸分析
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。(每一个方法都是一个栈帧,如果对象只在这个栈帧内没有被外部的的方法引用,说明他没有逃逸)
1 | public class EscapeTest { |
栈上分配
我们都知道Java中的对象都是在堆上分配的,而垃圾回收机制会回收堆中不再使用的对象,但是筛选可回收对象,回收对象还有整理内存都需要消耗时间。如果能够通过逃逸分析确定某些对象不会逃出方法之外,那就可以让这个对象在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
在一般应用中,如果不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了。
同步消除
线程同步本身比较耗,如果确定一个对象不会逃逸出线程,无法被其它线程访问到,那该对象的读写就不会存在竞争,对这个变量的同步措施就可以消除掉。单线程中是没有锁竞争。(锁和锁块内的对象不会逃逸出线程就可以把这个同步块取消)
标量替换
Java虚拟机中的原始数据类型(int,long等数值类型以及reference类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它称为聚合量,Java中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
不过上面都属于java后期的编译优化,和垃圾回收没什么太多关系,扯远了
垃圾回收涉及到的算法
什么是垃圾
垃圾就是不使用的一块内存空间。我们知道现在的计算机是源于冯诺依曼机。把计算机分为五部分,分别为运算器,控制器,存储器,输入设备,输出设备。而内存,硬,高速缓存和寄存器盘都算是存储器(这里面主要说的是内存而不是其他的存储器)。内存主要存储一些从硬盘或这输出输出设备传输过来的临时数据。当这些数据使用完了之后应该被清除,而不是一直占用内存空间,所以清除内存中不在使用的空间叫做垃圾回收。
垃圾的确认,上面是说垃圾是一块不在使用的内存,那么什么垃圾我们该如何确认?这里要说两种算法一种是引用计数算法,另一种是可达性分析算法。
垃圾的判定
引用计数算法:给对象添加一个引用计数器,每当有一个地方引用它时,计数器加1,当引用失效时就减1;任何时刻计数器为0的对象是不能在使用(也就是没有一个引用可以把堆内中的对象找到,或者是使用,这样这个对象就是一个死对象)。也就是内存中的垃圾。但是主流的JVM中没有使用引用算法来管理内存,主要原因是就是它很难解决对象之间相互循环引用的问题。
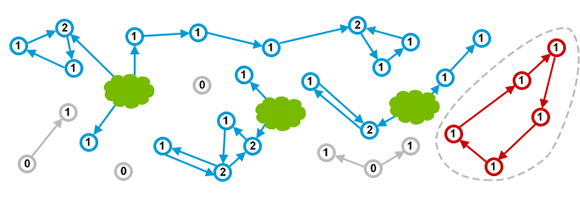
可达性算法:现在主流的JVM上使用的是可达性分析算法;可达性算法的基本思路就是通过很多“GC_ROOT”的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC_ROOT 没有任何引用链时,就说明对象是不可达的,没有一个引用可以找到这个对象,该对象就是死对象也就是可以被回收。
GC_ROOT的对象可以包括以下几种,1、虚拟机栈(栈帧中的本地变量表)中引用的对象,一般就是一个方法中的对象(一个栈帧就是一个方法,在递归的时候一个方法调用多次,也是多个栈帧);2、方法区中类静态属性引用的对象(一般静态对象和类信息一起都是存在方法区里);3、方法区常量引用的对象(存在常量池中,或者和类信息存储一起);4、本地方法栈JNI(java native interface)引用的对象。
垃圾回收的安全点(stop-the-world,并发收集,几种gc收集器)
上面说道一般会通过可达性算法来判定那些对象是否被回收,那HotSpot 虚拟机通过 GC Roots 枚举判定待回收的对象,通过安全点和安全区域确定 GC 的触发点,最后通过各种不同的回收算法完成垃圾回收。
GC Roots 枚举最大的困难点在于:检查范围比较大,并且必须在内存快照中进行,保证一致性,而且时间要求比较敏感。
在生产环境中,即使不考虑其它部分内存,仅仅 Java 堆内存就可达几百兆甚至上G,在此范围内完成 GC Roots 确定是一件很困难的事情;同时,在进行 GC Roots 枚举时,必须保证一致性,即所有正在运行的程序必须停顿(这种停顿就是stop-the-world,一般这种停顿会导致jvm性能下降,生成所谓的gc抖动),不能出现正在枚举 GC Roots,而程序还在跑的情况,这会导致 GC Roots 不断变化,产生数据不一致导致统计不准确的情况;最后,由于所有工作线程必须停顿以完成 GC 过程,在大并发高访问量情况下,这个时间必须非常短。(一般GCRoot枚举就是垃圾回收中标记的过程,他会把能用的都对象都存储到相关的OopMap中)
HotSpot 采用了一种 “准确式 GC” 的技术;该技术主要功能就是让虚拟机可以准确的知道内存中某个位置的数据类型是什么;比如某个内存位置到底是一个整型的变量,还是对某个对象的 reference;这样在进行 GC Roots 枚举时,只需要枚举 reference 类型的即可。在能够准确地确定 Java 堆和方法区等 reference 准确位置之后,HotSpot 就能极大地缩短 GC Roots 枚举时间。然后他引用了OopMap这个数据结构。
OopMap:记录对象引用关系的一个数据结构,它主要是用来查找GC Roots节点的,在 HotSpot 的 JIT 编译过程中,同样会插入相关指令来标明哪些位置存放的是对象引用,或者一些对象被创建和或者移动的时候,就会更新OopMap。这样在 GC 发生时,HotSpot 就可以直接扫描 OopMap 来获取引用对应堆上的信息,进行 GC Roots 枚举。
Safepoint:有了OopMap之后,如果为每一条指令都生成对应的 OopMap,那么将需要大量的额外空间,这样对导致 GC 成本很高,所以 HotSpot 只在 “特定位置” 记录这些信息,这些位置被称为 **安全点(Safepoint)**。一般进入安全点后就不会产生新的引用和对象。SafePoint保存了线程上下文中的任何东西,包括对象,指向对象或非对象的内部指针。
在JVM处于SafePoint时,所有在执行代码的Java线程将会被暂停。不与JVM交互的运行Native Code的能继续执行(如果需要通过JNI访问Java 对象,调用JAVA方法,从Native回到JAVA的话,则必须等到Safepoint结束。
一般进入SafePoint会在下面几种情况:1、垃圾收集。2、代码优化(JIT优化)。3、刷新代码缓存。4、类的重新定义(热部署)。5、各种调试工作(死锁检查,堆栈跟踪转储 Stack trace dump)
从线程状态的角度看,Waiting/Idle/Blocked/Running native code是处于SafePoint的,Running Java code是处在非SafePoint的状态。处于Safepoint时,Heap不能访问,Java代码不能执行。当全部Java线程都处于SafePoint状态时,JVM处于全局SafePoint,可用于执行:GC, 优化,Stack trace dump,锁偏向,类重定义等。我们的以下行为会导致进入SafePoint: 新生代耗尽,大对象分配导致的老年代耗尽,进入同步块等。
SafeRegion:安全区是指一段代码之中引用关系不发生变化,在这个区域中任何时候gc都是安全的。也就是在这段代码执行时候,不会产生浮动垃圾。
垃圾回收的几种算法
一般垃圾回收有三种收集方法,复制算法,标记-整理算法,标记-清除算法。垃圾回收可以防止内存泄漏(也不是绝对的),让程序能有充足的使用和分配对象的空间,避免OOM(out of Memory)异常。
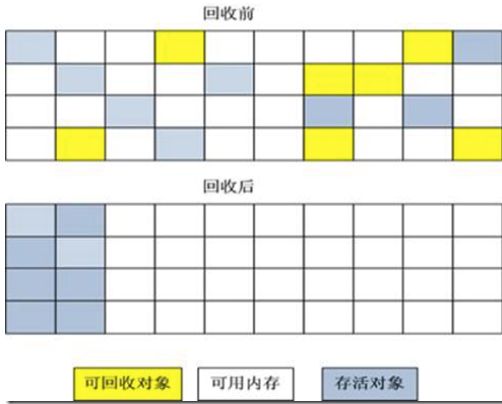
标记清除算法(Mark-Sweep):他是最基础收集算法。算法分两个阶段,标记和清除。首先要标记出来要统一回收的对象。也就是上面提到的可达性算法中不可达的对象,然后把这些对象进行标记。这种算法标记和清除的。效率都不高;同时标记清除后会产生大量不连续的内存碎片,空间碎片太多导致大对象分配内存时无法分配内存(一段连续的内存),可能导致触发又一次GC(Garbage collection) 。
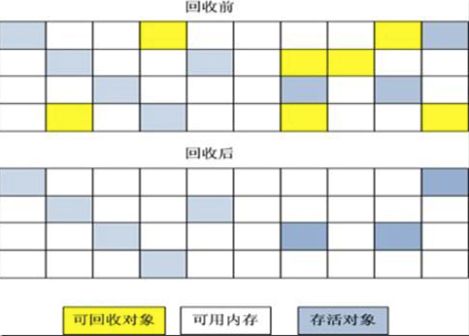
复制算法:它将可用的内存容量划分为大小不等的两块,每次只能使用其中的一块,当这一块内存用完了,就将还存活的对象复制到另外的一块内存,然后再把已经使用过的内存一次性清理掉。这样使得每次都对整个半区进行内存回收,内存分配的时候也不用考虑到内存碎片等复杂情况,只要移动堆顶指针,按照顺序分配内存即可,实现简单,运行高效。这种算法的待见就是将原来使用的内存大小缩小到一般。但是JVM实现Eden的垃圾回收的时候使用了这种算法,比例是8:1:1。Eden是8,survivor1和 survivor0都是1。每次使用的时候是8+1,这样相当于只使用10%的用于复制对象信息,这样既保证的效率又保证了空间的利用率。
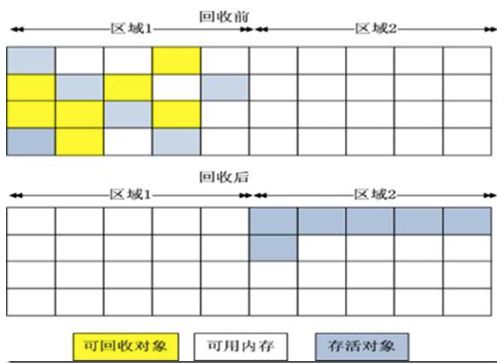
标记整理算法(Mark-Compact):复制算法在随着存活对象增加的时候,效率也会变低,更关键的是如果不想浪费50%的空间,就要在内存中所有对象都是100%存活的情况下,分配额外的内存空间,所以老年代是不能使用这种垃圾回收算法,所以有人提出来标记-整理算法,标记过程和标记清除算法一样,但后续的步骤不是对可回收的对象进行清理,而是让所有对象都向一段移动,然后直接对回收对象清理掉端已外的内存。
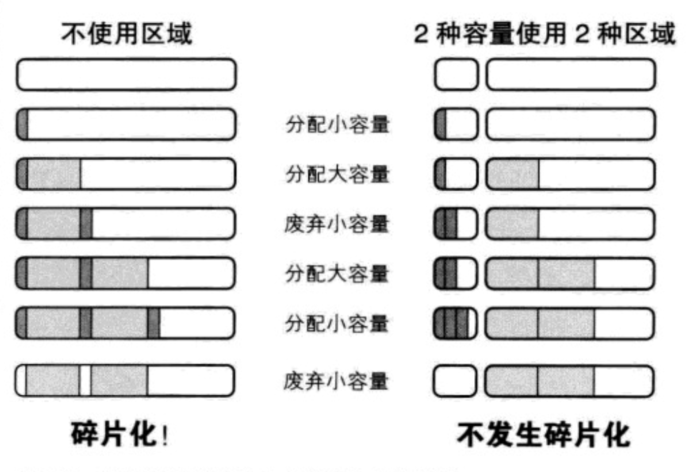
内存碎片化:碎片化是一个常常被谈到的问题,那什么是碎片化呢?碎片化是之存储器把好多小的数据或文件不连续的存储在内存或硬盘上,空闲页面趋向于散落在不连续的空间,很难再有足够长的连续物理内存页面分配。导致以后要分配连续的内存空间时却没有足够的空间,这样会导致内存或硬盘空间明明够大但是却没有连续的一块足够大空闲部分。
效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
内存整齐度:复制算法=标记/整理算法>标记/清除算法。
内存利用率:标记/整理算法=标记/清除算法>复制算法。
垃圾的分代收集
垃圾回收也是要分类的,不一样额垃圾不一样处理。
- 商业虚拟机一般都是使用分代收集算法。根据对象存活的周期,将Java的堆内存划分为新生代,老年代和持久代(1.8是MetaData Space)这样就可以根据各个年代的特点采用适当的收集算法。在新生代每次垃圾收集时都会发现大批量的对象死亡(不可达,新生代对象一般都是朝生夕死),只有少量存活,那就使用复制算法只需要付出少量存活对象的复制成本就可以完成收集。而老年代的对象存活率比较高,没有额外的空间分配担保,所以必须使用标记清除或者标记整理算法进行垃圾回收。
新生代
1、所用新创建的对象,都首先放在新生代中。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。
2、新生代一般被8:1:1的被分配,Eden是8,survivor1和 survivor0都是1。大部分对象在Eden(伊甸园)生成,回收时将一部分Eden中的存活的对象,放在survivor0区,然后清空Eden区,当这个survivor0被填满的时候,虚拟机会把survivor0和Eden区中的活对象复制到survivor1中,在把survival0和Eden中的数据清空,这时survivor0是空的。虚拟机就是通过这种方式将survivor0和survivor1中的数据进行来回交换,总有一个是survivor是空的。
3、当survival0存放不下survival1和Eden的对象就会存放到老年代区,如果老年代存放不下,那么就触发一次fullGC。一般虚拟级会进行判断,默认在survival中年龄大于16(默认)就会移到老年代,或者是大对象直接进入老年代。
4.新生代发生的GC也叫做Minor GC,MinorGC发生频率比较高(不一定等Eden区满了才触发)
老年代
1、存放一些生命周期比较长的对象,一般都在新生代经过了多次垃圾收集,或者是一个很大的对象。
2、一般老年代发生的GC是major gc也是Full GC,一般这样的情况比较少,一般Full GC也会触发minor GC,一般在Full GC的情况下,JVM的吞吐量会下降。老年代的对象一般生命周期长,标记存活率高,同时老年代的空间也会比新生代要打,一般是1:2左右。
持久代
一般也成永久代,一般GC很少回收这部分的数据,一般都是方法区。一般存放静态信息,Class信息和方法信息。一般在类加载的时候,会把整个属于这个类的信息,加载到方法区。在这个类使用完之后被GC时,一般会触发这个类的卸载,也就从方法区清除这个类相关信息。
minor gc 、major gc、full gc
肯定有人说,这三个长的这么像都什么意思。这三个gc就是上面分代gc的一种表现形式。老外很聪明把内存分成几部分,(也就是老年代,新生代,持久代),然后对不同的对象做不一样的处理,也就是分而治之。分别用不同的收集算法去实现,而不是一股脑的把垃圾都回收。上面也都是说了三种收集算法,其实也就是对应这三种不同gc。各有优点,处理不同的分代和不同程度情况下的垃圾回收。
minor gc:就是年轻代gc,也可以说是小型gc,年轻代一般都是朝生夕死的对象(说白了就是活不长的对象,也就是被一次使用,或者几次使用,完成使命就进入垃圾堆了)所以这种垃圾收集比较频繁,要求内存整齐度和效率比较高,使用的是复制算法,但是有不能一半一半的复制,所以找了survivor0和survivor1交换复制来实现复制算法,提高内存的利用率。
major gc:就是老年代gc(大型gc),老年代的上的对象生命周期一半都比较长,比如线程池对象,一些单例的对象,或者是大对象。一般都会伴随minor gc,因为jvm一般都是引用可达性算法,所以老年代的对象可能与新生代的对象存在引用关系,但是新生代对象又很多,所以要在新生代先minor gc一次(也不定每次都要minor gc),清除大多数无用对象,这样与下major gc分析引用关系会省一些时间。然后在开始major gc分析引用标记对象,(分析引用与标记对象是一起操作,尽管说此时可能是多线程的并发的,但是在安全区或者安全点中还是一个stop-the-world的状态)一般在老年代,垃圾回收器都会多次标记垃圾。所以老年代的回收时间会比较长,一般是新生代的10倍左右。一般老年代常用的就是CMS(标记清除)和G1(标记整理)
Full gc:full gc是整个jvm的内存空间中所有的垃圾都会被回收掉。也就是老年代,持久代,新生代的垃圾都会被干掉,然后重新分配空间,这里面一般都使用的是标记整理,这个时间就更长,而且full gc停顿的时间也更长。所以一般都避免full gc。
JVM里一个对象是怎么从对象变成垃圾的(垃圾回收的整个过程)
首先JVM创建对象在新生代,新生代中的对象被使用,当又有大量新对象进入的新代,新生代没有足够空间分配空间开始minor gc,开始标记对象,然后将可用(存活,被标记)的对象复制到survivor0或者survivor1中进行。然后jvm清空所有的新生代空间(Eden),这个时候会有一个判断即如果对象过大,或者在survival区域中待的比较久的对象就直接进入到老年代。也也就是minor gc,一般新生代的垃圾回收器有(g1、ParNew 多线程,Serial单线程,Parallel Scavenge 并行收集器->吞吐量优先收集器。同时它和CMS无法配合使用)。新生代不停的gc(因为很多对象类加载进来,创建对象被使用,程序要跑下去)。很多长时间对象和大对象就会填满老年代,当老年代没有足够的空间去存放新来的对象,他就把之前存进来的对象,进行分析标记看那些对象已经变成垃圾(可达性算法),由于是可达性算法,所以新生代也会被分析,看有没有对象和老年代关联,所以一般也都会触发minor gc;这种标记然后开始清除没有被标记的对象(垃圾)也就是major gc,major gc的垃圾回收器有(cms 、g1、Parallel old、serial old->一般当CMS内存不足的时候的备选项)。最后一种情况是full gc,full gc JVM里面没有可用的空间比如说老年代,或者方法区没有足够多内存去分配(比如cms 垃圾回收导致老年代碎片化严重,不能把新生代的对象放进去,或者方法区没有足够多的空间)都会引发full gc 。full gc一般会比较慢,调用的收集算法也是之前的算法。(一般长期存活和比较大的对象会直接进入老年代)
肯定有人会问,既然JVM已经有垃圾回收机制,但是为什么还会有OOM异常,首先JVM只是帮忙处理不用的对象,如果你的在JVM所有的对象都在用,同时有不能回收当然会报OOM了。同样GC也只能在安全区和安全点进行GC,在full gc完发现还是不够用,毕竟谁也不知道这个gc 释放的内存对于下次是否够用。如果你的机器频繁full gc 说明你离OOM已经不远了。
并行(Parallel):指多条垃圾收集器并行(一起)工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集器线程同时执行,(不一定是并行,也有可能是交替进行
),用户程序继续运行,而垃圾收集程序运行于另一个cup上。
垃圾回收优化的基本原则
JVM 优化的三个性能指标:吞吐率,内存占用,延迟时间
吞吐率:是指不考虑垃圾收集引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。
内存占用:衡量为了高效的运行,垃圾回收器需要的内存大小
延迟时间:衡量垃圾回收器最小化甚至消灭由垃圾回收器引起的暂停时间和应用抖动的能力
3进2原则(类似于CAP)
一项指标的提升,往往需要牺牲其他一项或者两项指标。换一句话说,一项指标的妥协通常是为了支持提升其他一项或者两项指标。然而,对于大多数应用来说,
很少有3项指标都非常重要,通常,一项或者两项比其他的更重要。由于始终需要各种权衡,那么知道哪项指标对应用是最有必要的就显得非常重要。所以一般优化只优化
其中的两个指标,而不是三个指标都要优化。
在优化JVM垃圾回收器的时候,有3项基本原则
1、在minor垃圾回收器中,最大量的对象被回收,这个被称为Minor GC回收原则。秉承这个原则可以减少由应用产生的full垃圾回收数量和频率,Full垃圾回收往往需要更长的时间,以致于应用无法达到延迟和吞吐量的需求。
2、更多的内存分配给垃圾回收器,也就是说更大的Java堆空间,垃圾回收器和应用在吞吐量和延迟上会表现得更好,这条原则被称为GC最大内存原则。
3、优化JVM垃圾回收器的3个指标中的2个,这个被称为2/3 GC优化原则
常有的几种JVM配置和JVM的指令行(没有监控就,没办法调优,同样不要为调优而调优)
jps(不是jsp,JVM Process Status Tool)虚拟机进程状态工具
查看所有的jvm进程,包括进程ID,进程启动的路径等等。
jps -l 输出主类的全类名,如果进程是jar包的话,输出jar路径(ElasticSearch的LVMID 4365)

jps-v输出虚拟机进程启动的JVM参数(这个可以看到好多参数,图中能看到jps的参数和ElasticSearch的JVM具体参数)

jps-m输出虚拟机进程启动的时候,传给main函数的参数(图中能看到jps 的参数和ElasticSearch的启动参数-d表示后台启动)

jps-q只输出LVMID,不显示其他信息

jstat(JVM Statistics Monitoring Tools)虚拟机统计信息监控工具
用于监控虚拟机各种运行时状态信息和命令行工具,他可以显示本地或者远程虚拟机进程中类加载、内垃圾回收、JIT编译等数据。一般都需要获取JVM进程,这一般就使用jps来获取。
jstat -gc lvmid监控Java堆状况,包括Eden区,两个survivor、老年代、永久代等容量、已用时间、GC时间合计等信息。

S0C (Survivor0 Capacity)Survivor0总容量; S0U (Survivor0 Use)Survivor0使用量;S1C (Survivor1 Capacity)Survivor1总容量;S1U (Survivor1 Use)Survivor1使用量; EC(Eden Capacity)伊甸园容量;EU(Eden Use)伊甸园使用量; OC(Old Capacity)老年代总容量;OU(Old Use)老年代使用量;MC(MetaData Capacity)MetaData总容量;MU(MetaData Use);CCSC(Compress Class Space Capacity)压缩类空间大小;
CCSU(Compress Class Space Use)压缩类空间大小使用;YGC(Young GC)新生代GC次数 ;YGCT(Young GC Time)新生代GC时间;FGC(Full GC)Full GC次数;FGCT(Full GC Time)Full GC时间。上面说的这些参数都是单位都是KB。其中Xmx=128M=131072KB;Xms=128M=131072KB。
S0总容量4352.0KB;S1总容量4325.0KB。(S0,S1大小一样)
S0使用量 69.1KB;S1使用量0.0KB,S0的使用量1.58%(说明现在S0在被使用,S1属于空闲状态)
Eden区的总容量34944KB,Eden使用量21961.9KB,使用率62.84%(伊甸园大小为34944KB,大约是S0,S1的8倍,占总比26.66%。S0+S1+Eden=新生代占总比33.30%。也就三分之一
Old区的总容量87424.0KB,Old的使用量是65446.2KB,使用率74.86%。总占比66.99%也就是三分之二。
MetaData区总容量54868KB,使用量51210.9KB。使用率93.33%
压缩类空间8080KB,使用量6906.9%;使用率85.48%。
YGC 新生代GC次数 48,总耗时0.723s,FGC FullGC次数6,FullGC时间0.84s。可以看出来YGC一次平均时间
0.0156秒,FullGC平均时间0.14秒,所以可以看出来FullGC时间比Young gc差10倍作用。这里ElasticSearch运行时间不长,但是我们可以看出来GC很频繁,应该是堆分配比较小,所以频繁GC,要扩大堆的大小,提高效率。
jstat -gcutil lvmid 监视内容与-gc基本相同,但是输出主要是Java堆各个区域使用最大最小空间。只不过他会把各个空间的使用百分比拿出来

S0的使用率0.74%,S1没有使用,Eden(E)使用率74.86%和我们上面差不多,Old(O)Old使用率74.86%,MetaData(M)使用率93.33%。CCS使用率85.47%。新生代时间是0.7秒,Full GC次数 6,FullGC花费时间0.117秒,GCT(GC总时间)0.817秒。
jstat -gcnew lvmid 监控新生代GC情况。
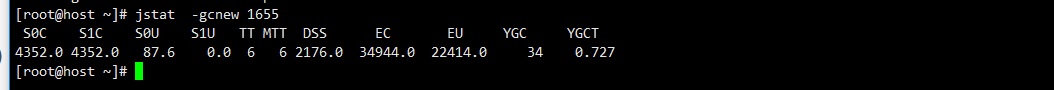
DSS(Desired survivor size):当前需要survivor(幸存区)的容量 (KB)(Eden区已满)。
TT(Tenuring threshold.): 持有次数限制(Survivor持有对象的次数)
MTT (Max Tenuring threshold.): 最大持有次数限制。(Survivor持有对象的最大次数)
S0、S1总容量4325KB,S0使用量87.6KB,S1使用0。持有次数和最大持有次数为6,survivor的期望容量2176KB(也就是还有2176KB对象是存活的,需要进入下一次周期),Eden区的总量34944.0KB,使用22414.0KB;GC了34次,消耗时间0.727秒。
jstat -gcold lvmid:监控老年代GC情况。
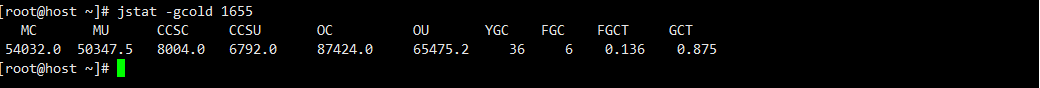
MetaData总量54032.0KB,使用量50347.5KB,压缩类空间大小8004.0KB,使用6792.0KB,老年代大小87424KB,使用量65475.2KB。新生代GC36次,FullGC 6次时间是0.136秒,GC总时间0.875秒。
jstat -class lvmid显示相关进程的类加载情况

Loaded:已经加载的类个数;Bytes:已经加载类的大小;Unload:没有加载类的个数;Bytes:没有加载类的大小了;Time:加载这些类所花费的时间。
加载了10386个类,大小是18626.5B;未加载类25个,大小28.3B;耗时11.23秒
jstat -gcmetacapacity lvmid 查看MetaDataSpace空间详情

MCMN(MetaData Capacity Min):MetaData空间初始最小空间(KB);MCMX(MetaData Capacity Max):MetaData空间最大容量;CCSMN(Compress Class Space Min):压缩类空间最小为容量;CCSMX(Compress Class Space Max)压缩类空间最大容量;
MetaData空间最小为0KB,最大为1095680.0KB(1070M这一点有点懵逼,估计是通过参数设置,因为我的这个主机最大512M内存)MetaData容量是54032.0KB(52.76M);压缩类空间最小为容量0KB,最大容量是1048576.0KB(1024M),压缩类空间大小8004.0KB。新生代GC 38次,FullGC 6次,FullGC时间0.136秒,GC总时间0.875秒
jstat -gccapacity lvmid与上面监控类似,但是主要输出java堆各个区域使用的最大最小空间

NGCMN( New Generation Capacity Min):新生代(Young)最小的容量;NGCMX( New Generation Capacity Max):新生代最大的容量;NGC(New Generation Capacity) 新生代容量;OGCMN(Old Generation Capacity Min):老年代带最小容量;OGCMX (Old Generation Capacity Max):老年代最大容量;
新生代最小容量43648.0KB,最大容量43648.0KB;新生代容量4352.0KB;S0容量4352.0KB;S1容量4352.0KB;Eden区大小34944.0KB;老年代最小容量87424.0KB,最大容量87424.0KB老年代容量87424.0KB;MetaData最小容量0,最大容量1095680.0KB,MetaData容量54032.0KB;压缩类空间最小为容量0KB,最大容量是1048576.0KB(1024M),压缩类空间大小8004.0KB。新生代GC60次,FullGC 6次。
jstat -gccause lvmid与-gcutil 功能一样,但是会额外输出导致上一次GC产生的原因.

LGCC(Last GC Cause):上一次GC原因;GCC (GC Cause):当前GC原因。
S0使用量0.0%,S1使用量106%,Eden区使用量74.04%,老年代使用量74.92%,MetaData使用量93.19%,CSS使用量84.88%,新生代GC次数61,新生代GC时间0.862秒,FullGC次数6,FullGC时间0.136秒,GC总时间0.999秒。上次GC原因 Allocation Failure(分配空间失败),当前没有GC
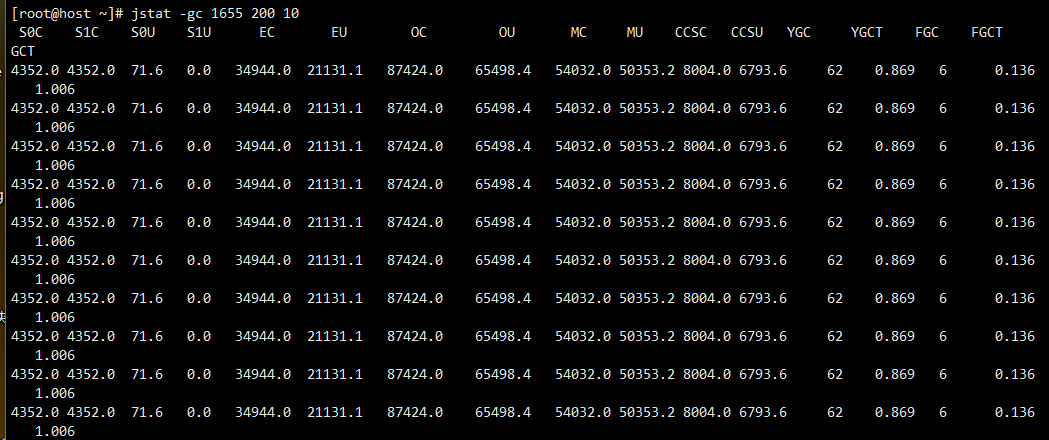
jstat -gc/gcutil/gcold... lvmid 200 10 使用 jstat -options 每200毫秒,20次。
jinfo (Configuration info java)显示Java配置信息。
注意在Linux里使用jinfo查看相关JVM的信息,要切换到启动JVM进程的用户要不然你就会收到(Unable to open socket file: target process not responding or HotSpot VM not loaded)。因为JVM的相关信息是存储在一个文件里,而在linux下面文件是隔离的。虚拟机具体参数表示-XX:+<option> 开启option 参数 例如 -XX:+PrintGCDetails 表示打印详细GC日志开启,相反的-XX:-<option> 关闭option参数 -XX:-UseParallelOldGC 不使用Parallel Old回收老年代和Parallel Scavenger回收新生代,-XX:<option>=<value> 将option参数的值设置为value例如 -XX:GCTimeRatio=99 即GC时间占总时间的比率1%。
jinfo -flag PrintGCDetails lvmid 查看打印详细GC日志

能看出来这个JVM并没有打印详细GC日志。在一般只有调试的时候打开,默认是关闭的。
jinfo -flag UseTLAB lvmid 优先使用本地线程缓存区分配对象,避免分配内存时的锁定过程。这个可以结合JMM,volatile去分析一下。

能看出来这个UserTALB这个参数已经生效
jinfo -flag GCTimeRatio lvmid GC时间占总时间的比率,默认值99,即允许1%的GC时间,仅在Parallel Scavenger 为回收器时生效。

可以看出来GCTimeRatio参数的值是99
jinfo -flag [+|-]< name >:设置或取消指定java虚拟机参数的布尔值。

开启打印详细GC日志。

关闭打印详细GC日志,当然不是什么参数都可以在这开启或者打开,一般都是要配置到配置文件里,然后让JVM重启才会生效,一般只有一些调试参数可以通过这方式开启。我也试过一些,但是好多都不成功

尝试设置GCTimeRatio的值,失败了。

关闭 UseTLAB失败
jinfo -flags lvmid显示这个JVM相关参数
1 | [es@host root]$ jinfo -flags 1655 |
jinfo -sysprops lvmid显示java系统的所欲配置参数,一般都能通过system.getproperty()能获取到的
1 | es@host root]$ jinfo -sysprops 1655 |
jmap(Memory Map for Java)命令用于生成堆转存储快照(dump文件)。
还可以用一些比较暴力的手段,比如通过-XX:+HeapDumpOnOutOfMemoryError参数,可以在虚拟机OOM之后自动生成dump文件,也可以通过-XX:+HeapDumpOnCtrlBreak参数使用Ctrl+Break键让虚拟机生成dump文件。
jmap -heap lvmid显示java堆的详细信息,如使用那种回收器,参数配置,分代情况等等,只有在linux和solaris平台有效,windows10也可以,别的我没试过。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52[es@host root]$ jmap -heap 1655
Attaching to process ID 1655, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.171-b11
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 134217728 (128.0MB)
NewSize = 44695552 (42.625MB)
MaxNewSize = 44695552 (42.625MB)
OldSize = 89522176 (85.375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 40239104 (38.375MB)
used = 31512760 (30.05290985107422MB)
free = 8726344 (8.322090148925781MB)
78.31377159889047% used
Eden Space:
capacity = 35782656 (34.125MB)
used = 31464952 (30.00731658935547MB)
free = 4317704 (4.117683410644531MB)
87.93352846697573% used
From Space:
capacity = 4456448 (4.25MB)
used = 47808 (0.04559326171875MB)
free = 4408640 (4.20440673828125MB)
1.0727826286764706% used
To Space:
capacity = 4456448 (4.25MB)
used = 0 (0.0MB)
free = 4456448 (4.25MB)
0.0% used
concurrent mark-sweep generation:
capacity = 89522176 (85.375MB)
used = 67081200 (63.97361755371094MB)
free = 22440976 (21.401382446289062MB)
74.93249493846083% used
15096 interned Strings occupying 2342736 bytes.ElasticSearch的JVM的堆参数,这是在Linux上的,JVM的新生代使用Parallel New收集器,老年代Concurrent Mark-Sweep GC收集器和一些其他信息如各个分区的大小和使用情况,这里就不一一列举了。这里的S0和S1变成了fromSpace和toSpace,这里他把新生代划分是S0或者S1+Eden。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51C:\Users\qjq>jmap -heap 18480
Attaching to process ID 18480, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
using thread-local object allocation.
Garbage-First (G1) GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 643825664 (614.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 1024
capacity = 1073741824 (1024.0MB)
used = 187700456 (179.0051040649414MB)
free = 886041368 (844.9948959350586MB)
17.480967193841934% used
G1 Young Generation:
Eden Space:
regions = 55
capacity = 106954752 (102.0MB)
used = 57671680 (55.0MB)
free = 49283072 (47.0MB)
53.92156862745098% used
Survivor Space:
regions = 7
capacity = 7340032 (7.0MB)
used = 7340032 (7.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 118
capacity = 154140672 (147.0MB)
used = 121640168 (116.0051040649414MB)
free = 32500504 (30.994895935058594MB)
78.91503677887171% used
58394 interned Strings occupying 6157416 bytes.这个是window10下面,eclipse的JVM的的堆情况,从这里我们可以看出eclipse使用的是G1垃圾回收器,同样G1的垃圾回收,年轻代和老年代的划分和上面描述的CMS垃圾回收的分区是不一样的,G1使用更小的区域Regions来划分空间;Survivor区,只划分了7个regions是100%使用,而不是S1和S0,eden和Survivor大小大概是8:1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25C:\Users\qjq>jmap -histo 18480
num #instances #bytes class name
----------------------------------------------
1: 283121 33384912 [C
2: 581380 18604160 java.util.HashMap$Node
3: 449913 14397216 org.eclipse.equinox.internal.p2.metadata.OSGiVersion
4: 326694 12343296 [Ljava.lang.Object;
5: 300441 12017640 java.util.LinkedHashMap$Entry
6: 99920 10036696 [Ljava.util.HashMap$Node;
7: 201877 8075080 org.eclipse.equinox.internal.p2.metadata.RequiredCapability
8: 92849 7621184 [I
9: 252250 6054000 java.lang.String
10: 80490 5896296 [B
……………………
……………………
8003: 1 16 sun.util.locale.provider.AuxLocaleProviderAdapter$NullProvider
8004: 1 16 sun.util.locale.provider.CalendarDataUtility$CalendarFieldValueNamesMapGetter
8005: 1 16 sun.util.locale.provider.CalendarDataUtility$CalendarWeekParameterGetter
8006: 1 16 sun.util.locale.provider.CalendarNameProviderImpl$LengthBasedComparator
8007: 1 16 sun.util.locale.provider.SPILocaleProviderAdapter
8008: 1 16 sun.util.locale.provider.TimeZoneNameUtility$TimeZoneNameGetter
8009: 1 16 sun.util.resources.LocaleData
8010: 1 16 sun.util.resources.LocaleData$LocaleDataResourceBundleControl
Total 4672630 195589424jmap -histo 18480显示堆中对象统计信息,包括类和实例数量、合计容量;这里面使用的是windows的操作命令,Linux也一样,这个是eclipse的JVM类加载多少个,第一个是序号,第二这个实例的数量,第三个是所占的字节大小,第四个是类的名称,可以看出来最先加载和创建应该是本地库的一些类和实例,然后是HashMap一般HashMap都会作为一些容器类使用,比如spring中的DefaultListableBeanFactory个类中的bean容器使用的是HashMap。最后还有一个汇总也就是有4672630个实例,占用195589424字节大小(186.528M)jmap -finalizerinfo 1655显示在F-Queue中等待Finalizer线程中执行finalizer方法对象。linux,window10都可以。
jmap -dump [live,] format=b,file=<fileName>生成Java堆转储快照,格式是bin,文件名是;其中子参数live表示说明是否只输出存活的对象。 当虚拟机进程对-dump选项没有响应时,可使用这个选项强制生成dump快照。
jhat(JVM Heap Analysis Tool)虚拟机堆转储快照分析工具
一般经常与jmap一起使用来分析jmap生成的堆转储快照,jhat内置了一个HTTP/HTML的微型服务器可以在浏览器上查看。(一般来说不太会有jhat去分析dump文件,因为比较消耗资源),会使用VisualVM,Eclipse MemoryAnalyzer、IBM HeapAnalyzer等工具。(不过我没用过)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18C:\Users\qjq>jps -l
18480
976 sun.tools.jps.Jps
C:\Users\qjq>jmap -dump:format=b,file=eclispse.bin 18480
Dumping heap to C:\Users\qjq\eclispse.bin ...
Heap dump file created
C:\Users\qjq>jhat eclispse.bin
Reading from eclispse.bin...
Dump file created Mon Jul 16 23:00:41 CST 2018
Snapshot read, resolving...
Resolving 2640380 objects...
Chasing references, expect 528 dots................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Eliminating duplicate references................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.之后就可以访问http://127.0.0.1:7000 来查看dump文件
jstack(Stack Trace for Java)用于生成虚拟机当前时刻的线程快照
线程快照就是当前虚拟机内每一条线程在执行的方法堆栈的集合,生成线程快照堆主要目的是定位线程出现长时间停顿的原有,如线程死锁,死循环,请求外部资源时间过长,都是导致线程长时间停顿的原因。注意JVM启动用户与执行jstack同一个用户
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80[es@host hsperfdata_es]$ jstack -l 1655
2018-07-16 23:38:48
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.171-b11 mixed mode):
"elasticsearch[w7p9LOx][http_server_worker][T#2]" #49 daemon prio=5 os_prio=0 tid=0x00007f27e4003000 nid=0x1eee runnable [0x00007f27e067a000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000fde47568> (a sun.nio.ch.Util$3)
- locked <0x00000000fde47550> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000fde84a80> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at io.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:752)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:408)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
"Attach Listener" #48 daemon prio=9 os_prio=0 tid=0x00007f27dc381800 nid=0x14fe waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
"elasticsearch[w7p9LOx][flush][T#1]" #47 daemon prio=5 os_prio=0 tid=0x00007f27f8024800 nid=0x7e1 waiting on condition [0x00007f27da70c000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000fb480148> (a org.elasticsearch.common.util.concurrent.EsExecutors$ExecutorScalingQueue)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
…………………………
…………………………
"Finalizer" #3 daemon prio=8 os_prio=0 tid=0x00007f28140af000 nid=0x67e in Object.wait() [0x00007f2804422000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000facba6f0> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)
- locked <0x00000000facba6f0> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:212)
Locked ownable synchronizers:
- None
"Reference Handler" #2 daemon prio=10 os_prio=0 tid=0x00007f28140aa800 nid=0x67d in Object.wait() [0x00007f2804523000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000facb4b88> (a java.lang.ref.Reference$Lock)
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
- locked <0x00000000facb4b88> (a java.lang.ref.Reference$Lock)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
Locked ownable synchronizers:
- None
"VM Thread" os_prio=0 tid=0x00007f28140a3000 nid=0x67c runnable
"Gang worker#0 (Parallel GC Threads)" os_prio=0 tid=0x00007f281401c000 nid=0x67a runnable
"Concurrent Mark-Sweep GC Thread" os_prio=0 tid=0x00007f281403e800 nid=0x67b runnable
"VM Periodic Task Thread" os_prio=0 tid=0x00007f28140f0800 nid=0x684 waiting on condition
JNI global references: 6398能看出来现在在堆栈里总共有48个线程,他们都排列顺序,这里我把部分的线程堆栈删除了,要不然太多了,我们能看出来这些线程大多数都是daemon线程,同时也能看出他们的优先级os_prio=0,由于是守护进程,所以系统优先级是0。我们能看出来有些线程是java的线程,有的是JVM线程比如CMS回收的线程(老年代垃圾回收,运行),有Parallel回收线程(年轻代垃圾回收,运行), VM周期性任务线程(VM Periodic Task Thread,运行),VM线程(运行)。
我们分析具体一个线程,比如#2线程,也就是Reference Handler线程,我们看到线程状态状态是WAITING,它执行的本地方法(object.wait()方法)。os_prio线程系统的优先级。nid是JVM中线程唯一表的标识, tid:线程id,
<0x00000000facb4b88>这个地址,是这个线程在这个地址等待,而且锁在这个地址。没有锁定可拥有的同步器:。0x00007f2804523000线程起始地址。JNI总共的引用个数6398个。(我们可以看出来四个JVM系统线程没有prio。思考一下?)线程的各个状态:
New: 当线程对象创建时存在的状态,此时线程不可能执行;
Runnable:当调用thread.start()后,线程变成为Runnable状态。只要得到CPU,就可以执行;
Running:线程正在执行;
Waiting:执行thread.join()或在锁对象调用obj.wait()等情况就会进该状态,表明线程正处于等待某个资源或条件发生来唤醒自己;
Timed_Waiting:执行Thread.sleep(long)、thread.join(long)或obj.wait(long)等就会进该状态,与Waiting的区别在于Timed_Waiting的等待有时间限制;
Blocked:如果进入同步方法或同步代码块,没有获取到锁,则会进入该状态;
Dead:线程执行完毕,或者抛出了未捕获的异常之后,会进入dead状态,表示该线程结束其次,对于jstack日志,我们要着重关注如下关键信息;
Deadlock:表示有死锁;
Waiting on condition:等待某个资源或条件发生来唤醒自己。具体需要结合jstacktrace来分析,比如线程正在sleep,网络读写繁忙而等待;
Blocked:阻塞;
Waiting on monitor entry:在等待获取锁;
jstack -m lvmid如果调用本地方法,可以显示C/C++的堆栈,很长而且没看怎么懂就不贴出来了jstack -F lvmid当正常的请求不被响应时,强制输出堆栈信息。这里面的F(Force)

其他杂项
- CCSU的由来
在Java8以前,有一个选项是UseCompressedOops。所谓OOPS是指“ordinary object pointers“,就是原始指针。Java Runtime可以用这个指针直接访问指针对应的内存,做相应的操作(比如发起GC时做copy and sweep)。64bit的JVM出现后,OOPS的尺寸也变成了64bit,比之前的大了一倍。这会引入性能损耗,占的内存double了,并且同尺寸的CPU Cache要少存一倍的OOPS。于是就有了UseCompressedOops这个选项。打开后,OOPS变成了32bit。但32bit的base是8,所以能引用的空间是32GB——这远大于目前经常给jvm进程内存分配的空间。一般建议不要给JVM太大的内存,因为堆(Heap)太大,GC停顿实在是太久了。很多开发者喜欢在大内存机器上开多个JVM进程,每个给最大8G以下的内存。从JDK6_u23开始UseCompressedOops被默认打开了。因此既能享受64bit带来的好处,又避免了64bit带来的性能损耗。如果你有机会使用超过32G的堆内存,记得把这个选项关了。到了Java8,永久代被干掉了,由了MetaDataSpace的概念,存储jvm中的元数据,包括byte code,class等信息。Java8在UseCompressedOops之外,额外增加了一个新选项叫做UseCompressedClassPointer。这个选项打开后,class信息中的指针也用32bit的Compressed版本。而这些指针指向的空间被称作Compressed Class Space。默认大小是1G,但可以通过CompressedClassSpaceSize调整。如果你的java程序引用了太多的包,有可能会造成这个空间不够用,于是会看到java.lang.OutOfMemoryError: Compressed class space这时,一般调大CompreseedClassSpaceSize就可以了。








