MySQL的死锁
前言
I have a pen I have an apple Ugh Apple pen 这首PPAP大多数人都应该听过,不过今天不是讨论唱歌而是一个和PPAP差不多的事情 I have a MySQL I have DeadLock Ugh MySQL-DeadLock。 MySQL的死锁。
什么是死锁
死锁(DeadLock):当两个以上的运算单元,双方都在等待对方停止执行,以获取系统资源,但是没有一方提前退出时,就称为死锁。一般出现死锁会满足以下四种情况:
- 互斥条件:一个资源每次只能被一个运算单元使用。
- 持有和等待:一个运算单元可以在等待时持有系统资源,保持不释放。
- 禁止抢占:运算单元持有资源,在使用完之前不可以被强行退出。
- 循环等待:一系列运算单元互相持有其他运算单元所需要的资源。
只要破坏以上四个条件中的任意一个就可以解决这个死锁问题,这也是后面解决死锁问题的基本思路。
在操作系统里资源持有的维度是进程,所以上述运算单元可以理解为一个进程(这种死锁一般是指操作系统维度的进程管理)。根本原因还是因为并发和资源的分配的问题。
MySQL加锁的过程
之前文章有讨论MySQL的锁和一些基本加锁规则MySQL中的锁和MVCC。这里只重复一个规则,MySQL是两段加锁,加锁和解锁是分开的,加锁的时候只加锁,不释放锁,释放锁的时候是在执行完之后把所有的锁都释放掉(不过是在同一个事务里)。在这个两段加锁的逻辑里我们就看到禁止抢占,持有和等待两个条件,也就是加锁的资源要等执行完了才会释放。
| 事务 | 加锁与释放锁 |
|---|---|
| begin | |
| insert into … | 加锁(行锁,间隙锁) |
| update ….. | 加锁(行锁,间隙锁) |
| commit | |
| 释放 insert into的锁,释放update的锁 |
MySQL由于使用了MVCC的模式,所以一般在读取的收都不会加锁,使用的是快照读,只有在update,delete,insert的时候才会进行当前读的情况才会出现死锁。关于当前读和快照读我在上个关于MySQL的文章中也有说。不过除了这些MySQL也提供update、insert 的扩展比如insert into from select、select for update、insert for update这种语句在索引使用不正确的情况下也会出现死锁。
InnoDB引擎是如何加锁的
关于InnoDB是如何加锁过程,是一个很复杂事情,而且也需要具体情况具体分析。你在分析一条SQL加锁的过程一般,都要提前了解一些关于你使用MySQL的隔离级别,你使用MySQL版本,你的表里面里的索引结构,比如是主键索引、二级索引、唯一索引、MySQL的执行计划(会不会出现索引合并)很多因素。比如下面这两条语句的分析
主键索引+隔离级别RC
1 | ----id是主键索引 隔离级别是RC |
SQL1:不加锁,因为有MVCC的存在,读不加锁。
SQL2:对id = 12 的主键索引加X锁,主键索引加锁。
加锁过程:id是主键索引,直接锁定主键索引。(锁是加在索引上的)
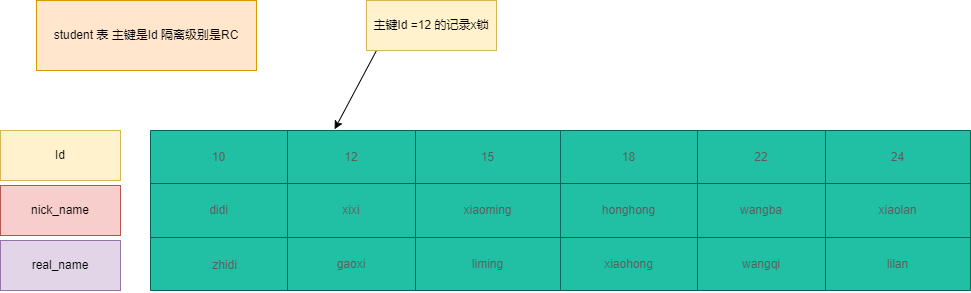
唯一索引+隔离级别RC
1 | ---- name是唯一索引 隔离级别是RC id是主键索引 id =15 nick_name = 'xiaoming' |
SQL3:加两个锁,即name的唯一索引的X锁和id=15的主键锁。
加锁过程:nick_name是唯一索引,id是主键。我们知道MySQL是聚簇索引,所以数据都存在主键索引内容里。在查询过程种需要回表。所以当加锁的时候也是遵循这个流程。首先找到nick_name= xiaoming的索引项,然后加X锁。同时回表查询数据获取到id=15的数据。然后在对主键id=15的索引项加锁。
为什么加两个锁,一个锁不够用吗?
如果只在唯一索引项加锁,没有主键索引加锁,那么后续操作如果根据主键索引去删除,会导致锁失效。并发的update感受不到delete的存在,导致更新失败。在这个栗子,可以分析加锁过程是从二级索引到主键索引都要加锁。加锁过程是先从二级索引加锁,然后在加一级索引
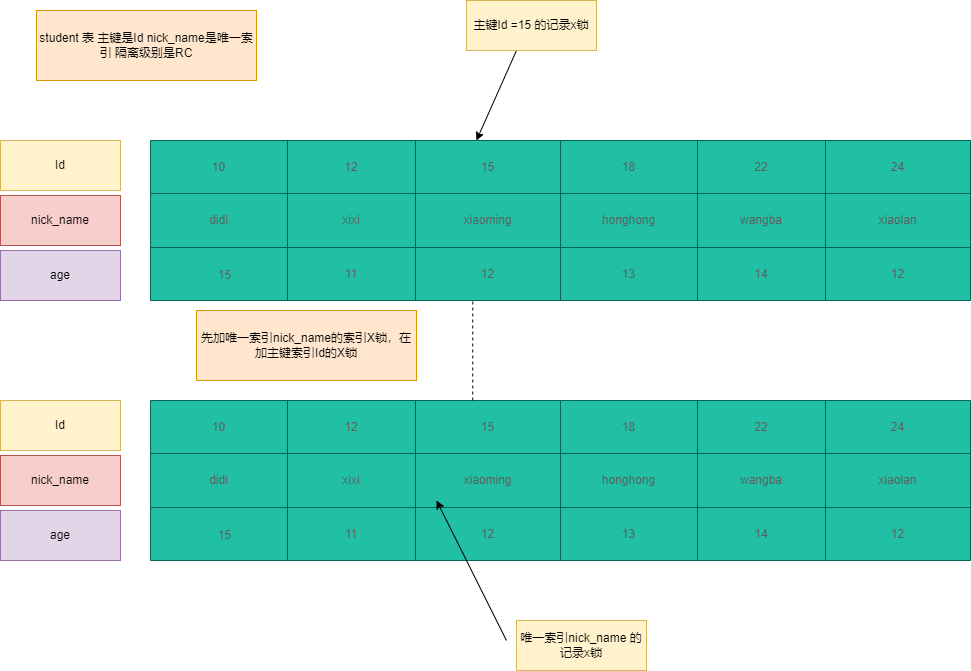
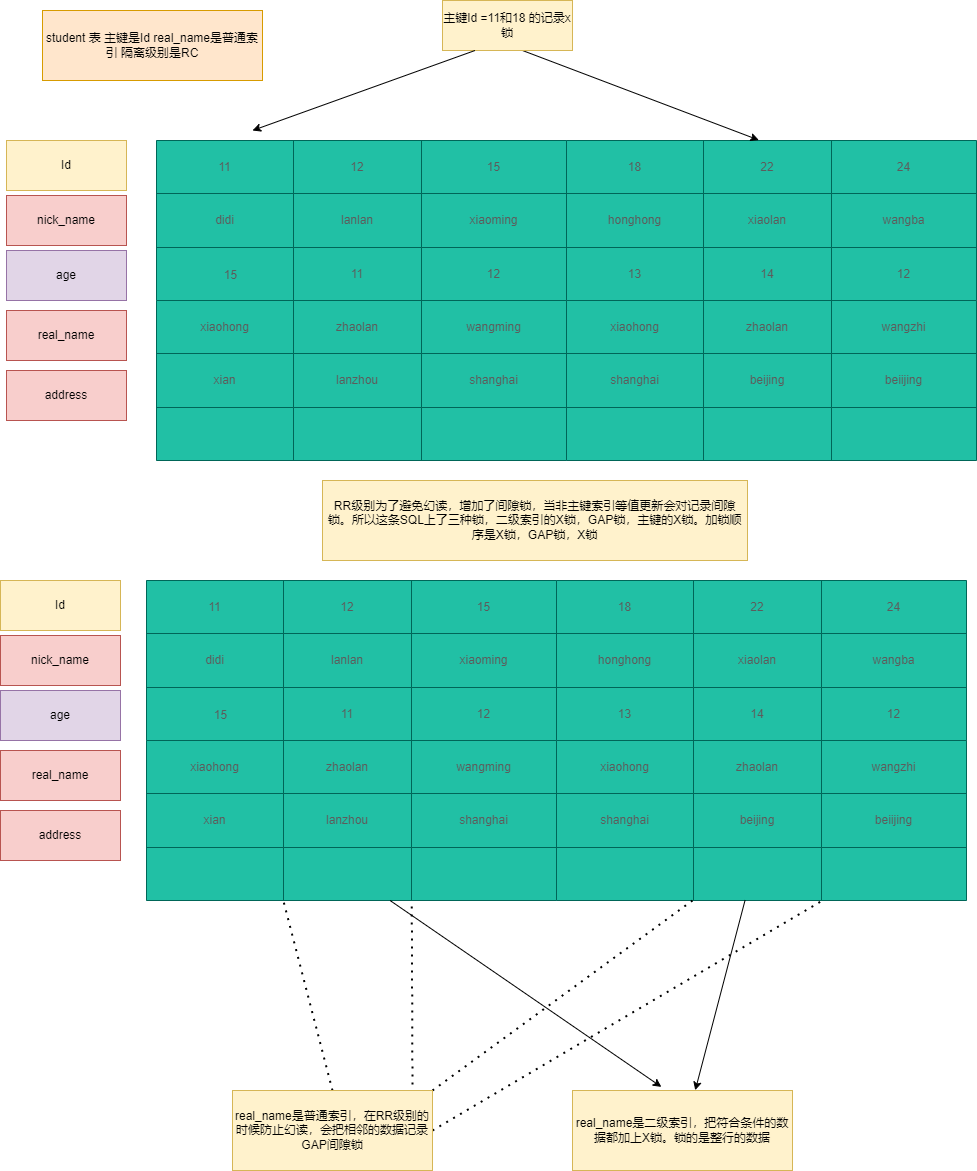
非唯一索引+隔离级别RC
1 | -----real_name是非唯一索引 隔离级别是RC id是主键索引 id=11 和 id =18 real_name = 'xiaohong' |
SQL4:加两个锁,在二级索引real_name= ‘xiaohong’加X锁,同时把id=11和id=18的主键索引加X锁。
加锁过程:首先查询real_name=’xiaohong’,然后把符合过滤数据加X锁,然后回表查询主键索引,在对主键索引id=11和id=18加X锁。
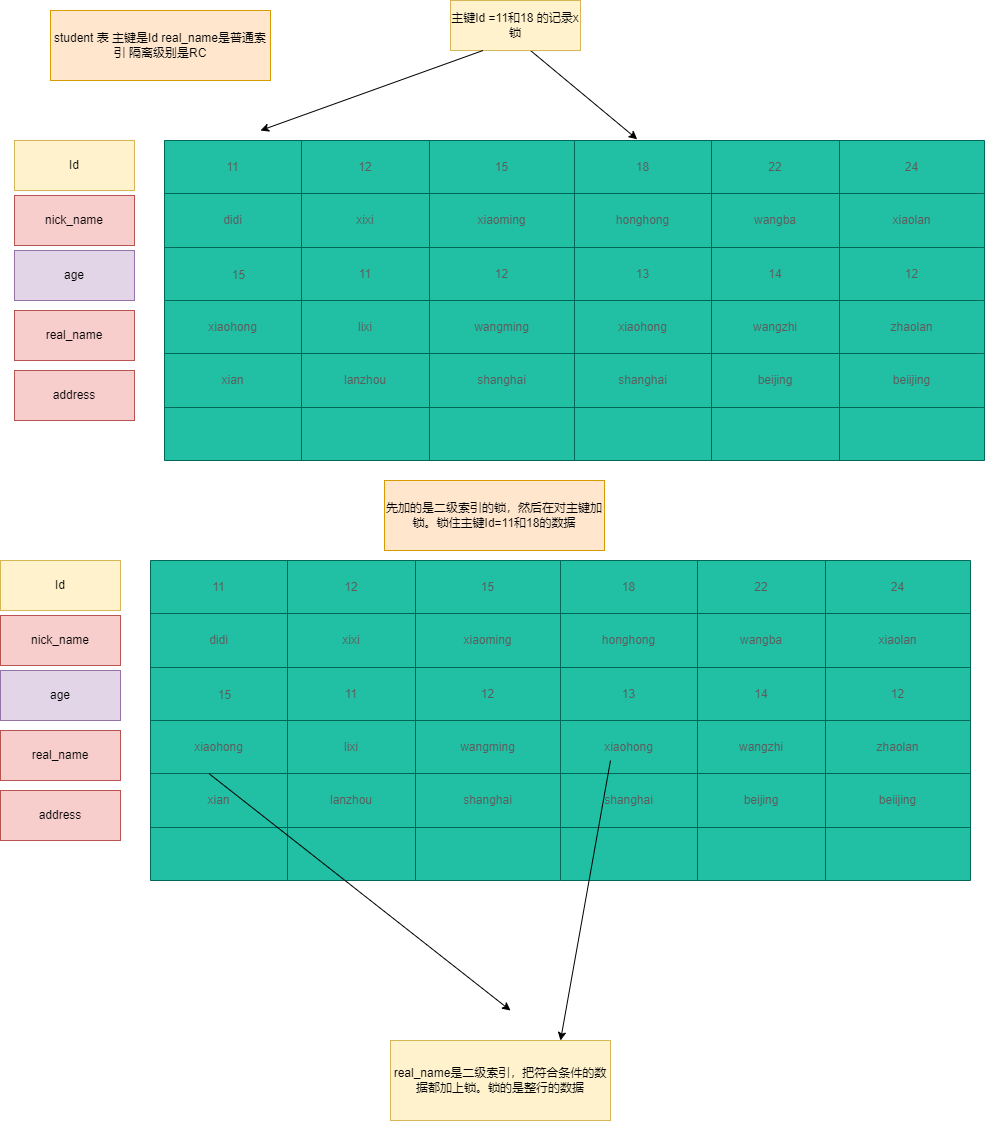
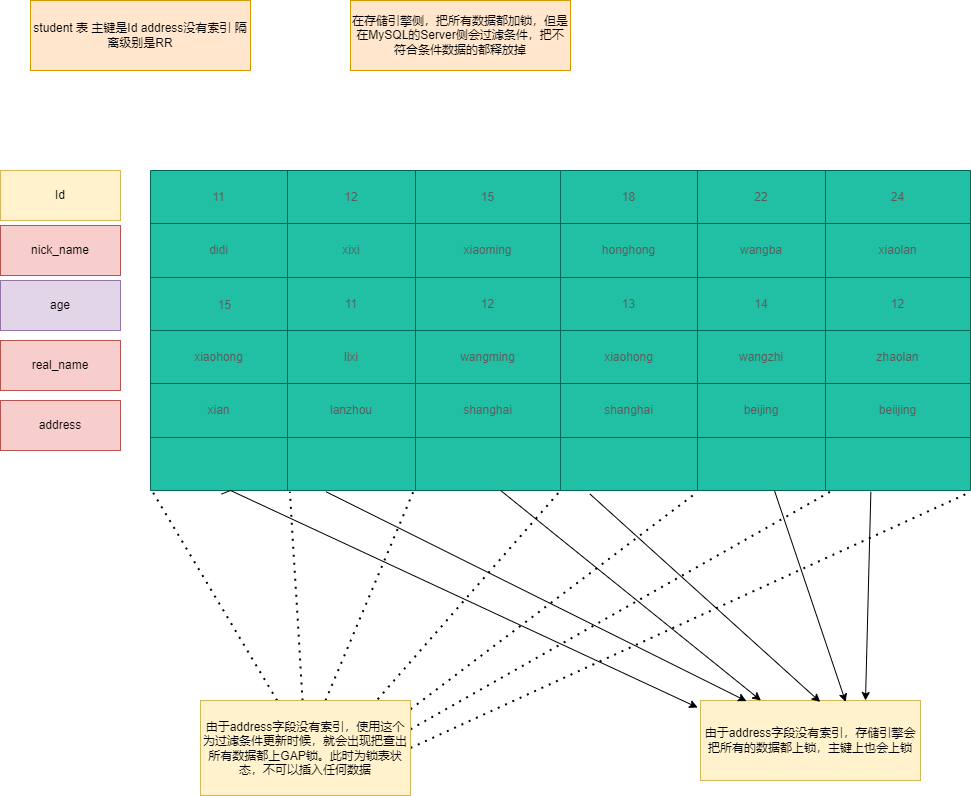
非索引+隔离级别RC
1 | ---- address 不是索引,隔离级别是RC id = 22 和 id = 24 |
SQL5:加一个锁(主键索引的锁),首先在存储引擎层面把每条数据都加锁(全表扫描),把对应主键Id数据全部加X锁。但是在MySQL-Server层会进行优化,把不符合锁的数据锁释放掉。(违背了2PL原则),不过这种方式提高效率,但是存储引擎层面的所有数据加锁不会省略。
加锁过程:由于address字段没有索引存储引擎会全表扫描,把所有数据都加上X锁(逻辑上是表锁),也就是所有的主键id都加上X锁。MySQL-Server在过滤条件时候会调用unlock_row方法,把不满足数据都得锁都释放掉,在Server层保证满足记录上锁,提高了效率。不过这种方法违背了两端加锁原则。加锁顺序address数据上的X锁,主键索引的X锁。

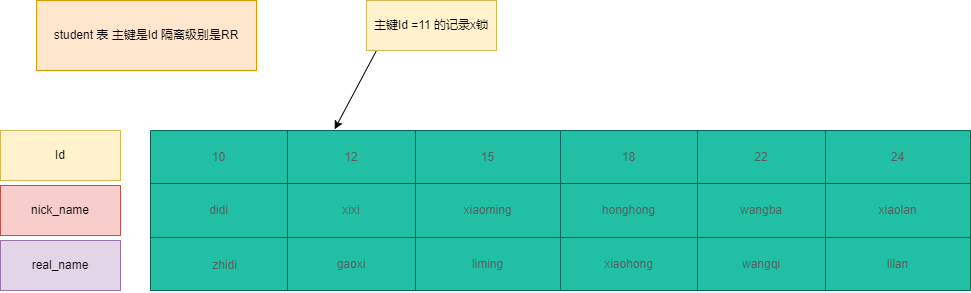
主键索引+隔离级别RR
1 | ---- id 是主键索引 隔离级别是RR |
SQL6:对id = 12 的主键索引加X锁,主键索引加锁。
加锁过程:id是主键索引,直接锁定主键索引。(其实加的是Next-Key锁只不过退化(升级)成X锁)
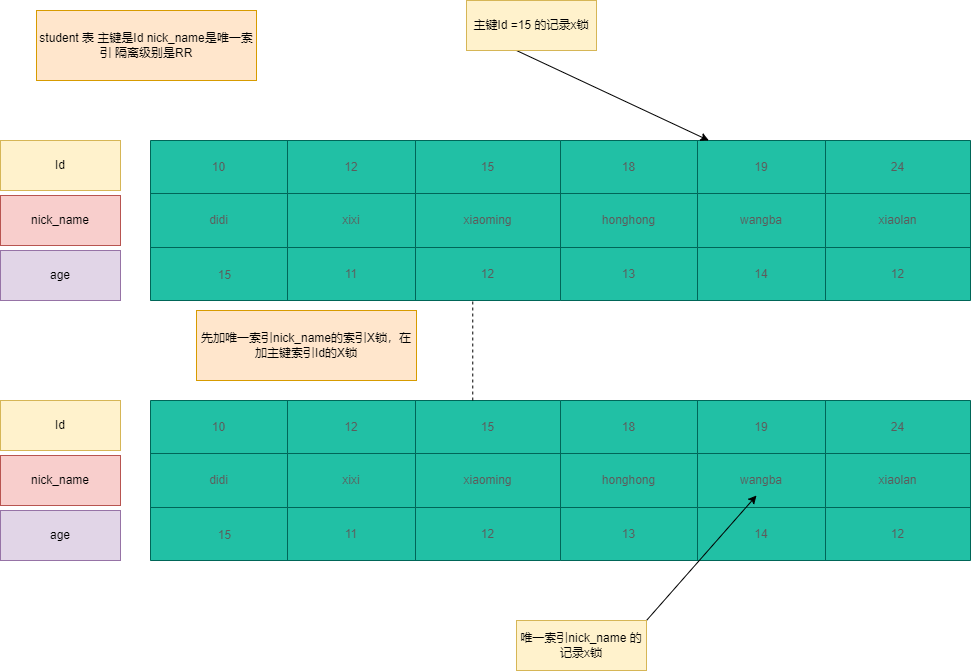
唯一索引+隔离级别RR
1 | ---- nick_name 是唯一索引 隔离级别是RR id是主键索引 id =19 |
SQL7:加两个锁,在唯一索引nick_name= ‘wangba’加X锁,同时id=19的主键索引加X锁。
加锁过程:首先查询nick_name=’wangba’,然后把符合过滤数据加X锁,然后回表查询主键索引,在对主键索引id=11加X锁。准确点描述这种模式也加了GAP锁,只不过是等值查找退化成了X锁。(其实加的是Next-Key锁只不过退化(升级)成X锁)
非唯一索引+隔离级别RR
1 | ---- real_name 是非唯一索引 隔离级别是RC id是主键索引 id = 22 和 id = 12 real_name = 'zhaolan' |
SQL8:加三个锁,real_name索引上索引的数据加X锁,在real_name=’xiaolan’的数据附近加GAP锁,最后在主键id=12 和 id = 22 加X锁。
加锁过程:在real_name索引加X锁,由于隔离级别是RR保证不幻读,在rea_name=’xiaolan’数据附近加3个GPA锁,最后在主键id =12 和id =22 的数据上加X锁,保证数据不会被更新。
为啥加GAP锁可以解决幻读问题
GPA锁是间隙锁,间隙锁保证两条数据中间不可以插入数据。幻读指同一个事务两次查询获取到的记录和记录数量相同,不会出现数据修改,X锁保证,数量一致,GPA锁保证,即重复读取数据一致,这里的读指的是当前读。因为B+树是一个由顺序的树,相近的数据都是有顺序且连续分布,当新的数据插入会发现GAP锁(间隙锁),不会使新的数据不会被插入。保证了两次当读取数据数量使一致的。加GAP锁使从第一条满足条件开始加,一直加到第一条不满足条的数据对于real_name的索引。
为啥SQL7不需要加GAP锁而SQL8 需要加GAP锁。
因为GAP(间隙锁)保证使两次读取的数量一致,而SQL7种nick_name索引字段使唯一索引,只能产生一条数据,不会存在数据数量不一致的问题(永远都只有一条),X锁保证数据读取时候不会被删除。所以也就不需要使用GAP锁去保证间隙插入数据。唯一索引解决了这个问题。(这里只是讨论等值,如果是范围update也会不一样,范围会扩大)
非索引+隔离级别RR
1 | ---- address 是没有索引 id 是主键索引 隔离级别RR |
SQL9:主键索引所有数据都会被加X锁和GAP锁。在使用(semi-consistent read) 半一致性读的熟,会提前释放X锁和GAP锁。
加锁过程:由于全表扫描,会把主键索引(聚簇索引)全部加X锁,由于RR隔离级别,防止插入数据,在所有数据都会加上GAP锁,这个加锁时间超级长。而且会导致整个表都被锁死。除非开放semi-consistent read,会把不满足查询条件的数据锁过滤掉。提前释放掉,类似RC种的处理。不过打开semi-consistent read也会导致其他问题,如果不是很适合不推荐使用。
加锁顺序address所有数据的X锁,GAP锁主键索引的X锁
非索引+隔离级别Serializable
1 | ---- address 是没有索引 id 是主键索引 隔离级别Serializable |
SQL10:不会加锁
加锁过程:隔离级别Serializable是串行执行的SQL,不会有并行操作。所以不需要加锁就可以。
总结一下。MySQL主要是给索引加锁,而不是给数据加锁(数据加锁是通过给索引加锁去体现的)。所以在分析加锁的时候,分析建表的索引和隔离级别,在不同隔离级别锁加的类型也不一样。在走到索引和没走到索引时候也不一样。所以遇到问题还是要具体分析。我们在写SQL时候就要尽量避免锁大批量数据,这会导致MySQL性能下降。不过一般情况分析死锁都是通过InnDB引擎日志去分析,日志里面有详细的MySQL执行的过程。
分析加锁过程可以使用select * from performance_schema.data_locks;查看加锁状态和过程
本篇文章都是基于MySQL5.7版本讨论。MySQL8.0版本加锁逻辑发生变化
如何排查分析MySQL死锁
当你的程序出现死锁的时候,会有异常抛出了。这个时候你会看到这样的错误栈信息。
1 | org.springframework.dao.DeadlockLoserDataAccessException: Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction The error may involve defaultParameterMap The error occurred while setting parameters SQL: update dpm_doctor_patient_tag_mapping set is_del = 1, update_time = now() where is_del = 0 AND tag_id = ? AND patient_id = ? AND biz_id = ? |
DeadlockLoserDataAccessException死锁的异常,导致死锁的SQL,我们能从这个地方看出来这个是一个update语句导致的死锁。
首先不要慌,死锁MySQL会帮你把死锁的语句停止执行,所以不会产生数据太大异常。数据库不会因此被死锁拖垮,至少我没碰到过被死锁拖垮,一般都是因为复杂查询计算过多或者查询时候没有带分页全表扫描数据,然后把整张表几百万数据吐出导致内存和MySQL的IO都受不了。
查看死锁InnoDB日志
执行 show engine innodb status 查看innodb的日志 。show engine innodb status显示的不是当前状态,而是过去某个时间范围内InnoDB存储引擎的状态。
show engine innodb status主要包括以下几个部分:
| BACKGROUND THREAD | 后台Master线程 |
|---|---|
| SEMAPHORES | 信号量信息 |
| LATEST DETECTED DEADLOCK | 最近一次死锁信息,只有产生过死锁才会有 |
| TRANSACTIONS | 事务信息 |
| FILE I/O | IO Thread信息 |
| INSERT BUFFER AND ADAPTIVE HASH INDEX | INSERT BUFFER和自适应HASH索引 |
| LOG | 日志 |
| BUFFER POOL AND MEMORY | BUFFER POOL和内存 |
| INDIVIDUAL BUFFER POOL INFO | 如果设置了多个BUFFER POOL实例,这里显示每个BUFFER POOL信息。可通过innodb_buffer_pool_instances参数设置 |
| ROW OPERATIONS | 行操作统计信息 |
| END OF INNODB MONITOR OUTPU | 输出结束语 |
我们不怎么看其他的InnoDB线程的信息,主要关注死锁信息LATEST DETECTED DEADLOCK。其他的线程状态主要是给InnoDB引擎调优用的,目前对于死锁问题用不上,后面可以单独写博客来讨论。
执行完show engine innodb statusInnoDB日志信息。
1 |
|
锁报错分析
我们来分析一下这个InnoDB最后执行的内容。这个日志打印的最近31秒的日志信息,这里主要分析在LATEST DETECTED DEADLOCK以后的信息。大致翻译一下上面的内容
事务1,事务Id =152788457。表里数据,用三条锁三条,然后等待第四条记录上锁。然后锁阻塞了,阻塞线程Id是 12966513线程 阻塞 12966516线程。查找数据为了更新(是一个更新数据的一个当前读的状态)
1 | --- update语句 patient_id和tag_id是普通索引。 |
等待锁被释放,记录锁定在空间(id)306 页编号 79894的主键索引的表上,这次事务(事务Id 152788457)使用的是X 锁,没有GAP锁,5号堆(heap)的物理记录.(update语句是需要当前查,所以在更新数据要查询最新的数据,然后把内容更新。这里表索引是tag_id和patient_id字段。)
事务2,事务Id=152788460。表里数据,用三条锁三条,然后等待第四条记录上锁。然后锁阻塞了,线程Id是 12966513 。查找数据为了更新(是一个更新数据的一个当前读的状态)
1 | --- update语句 patient_id和tag_id是普通索引。 |
持有锁,记录锁定在空间(id)306 页编号 79894的主键索引的表上,这次事务(事务Id 152788460)使用的是X 锁,没有GAP锁,5号堆(heap)的物理记录.
等待释放锁,记录被锁在空间(Id)306 页编号110314的 idx_tag_id的索引的表上。这次事务(事务Id 152788460)使用的是X 锁,没有GAP锁,434号堆(heap)的物理记录。
我们回滚了这两条事务。
翻译完上面的内容,我们整理一下思路,然后仔细看下,细节
1 | 事务1 Id 152788457 在执行update语句时等待主键索引上的行锁释放( WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 306 page no 79894 n bits 200 index `PRIMARY`) |
分析原因时索引加锁顺序导致死锁,根据上面我们之前的分析,是在二级索引加锁的时候发生的问题。
我们分析一下SQL的执行计划
1 | explain |
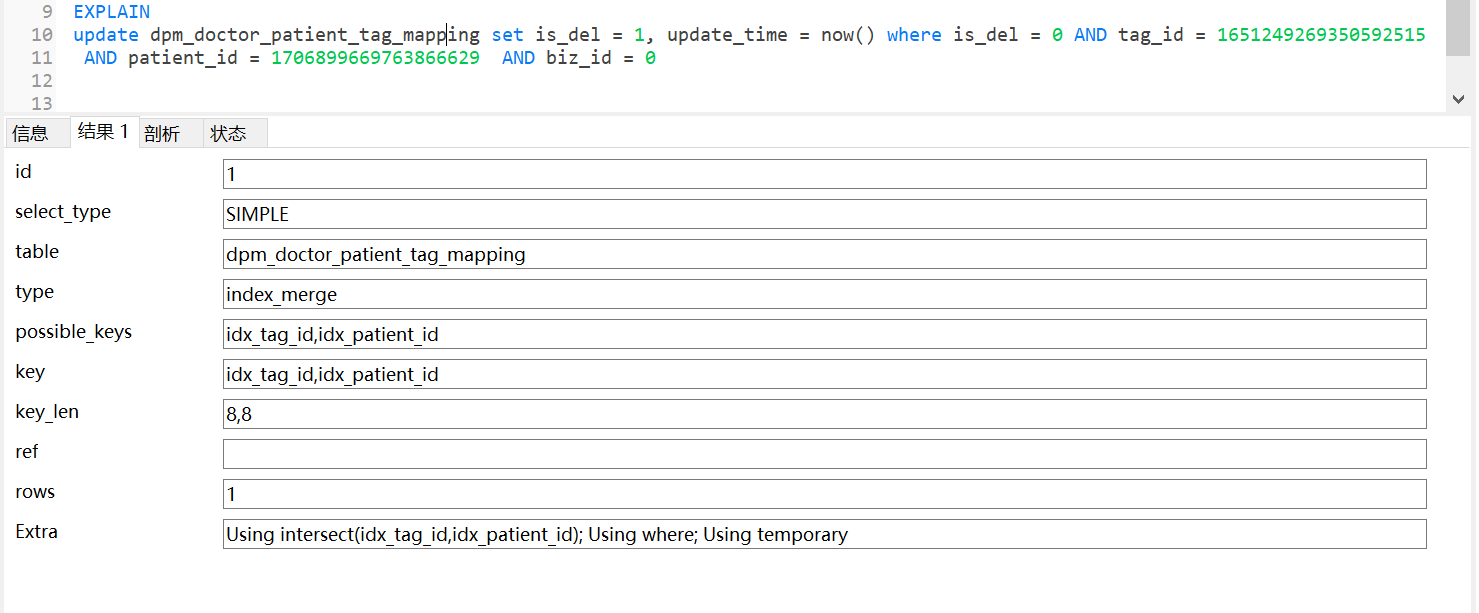
通过看执行计划,可以发现,update语句用到了索引合并,也就是这条语句既用到了 idx_tag_id索引,又用到了 idx_patient_id索引,Using intersect(idx_tag_id,idx_patient_id)的意思是通过两个索引获取交集。
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
SQL语句的执行过程
1 | update dpm_doctor_patient_tag_mapping set is_del = 1, update_time = now() where is_del = 0 AND tag_id = 1651249269350592515 AND patient_id = 1706899669763866629 AND biz_id = 0 |
MySQL会根据 tag_id= 1651249269350592515这个条件,利用 idx_tag_id 索引找到叶子节点中保存的id值;同时会根据 patient_id = 1706899669763866629这个条件,利用 idx_paient_id 索引找到叶子节点中保存的id值;然后将找到的两组id值取交集,终通过交集后的id回表,也就是通过 PRIMARY 索引找到叶子节点中保存的行数据。
这里可能很多人会有疑问了,idx_tag_id 已经是一个索引了,通过这个索引终只能找到多一条数据,那MySQL优化器为啥还要用两个索引取交集,再回表进行查询呢,这样不是多了一次 idx_patient_id 索引查找的过程么。我们来分析一下这两种情况执行过程。
第一种 只用idx_tag_id索引 :
- 根据
tag_id= 1651249269350592515查询条件,利用idx_tag_id索引找到叶子节点中保存的id值; - 通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
- 再通过
patient_id =1706899669763866629条件对找到的行数据进行过滤。
第二种 用到索引合并 Using intersect(idx_tag_id,idx_patient_id):
- 根据 ``tag_id = 1651249269350592515
查询条件,利用idx_tag_id` 索引找到叶子节点中保存的id值; - 根据
patient_id =1706899669763866629查询条件,利用idx_patient_id索引找到叶子节点中保存的id值; - 将1/2中找到的id值取交集,然后利用PRIMARY索引找到叶子节点中保存的行数据
上边两种情况,主要区别在于,种是先通过一个索引把数据找到后,再用其它查询条件进行过滤;第二种是先通过两个索引查出的id值取交集,如果取交集后还存在id值,则再去回表将数据取出来。
当优化器认为第二种情况执行成本比种要小时,就会出现索引合并。
解决方法
从代码层面
- where 查询条件中,只传
tag_id; - 使用
force index(idx_tag_id)强制查询语句使用idx_tag_id索引; - where 查询条件后边直接用 id 字段,通过主键去更新。
从MySQL层面
- 删除
idx_patient_id索引或者建一个包含这俩列的联合索引; - 将MySQL优化器的
index merge优化关闭。
总结
本来是一次,线上问题排查。然后通过这个问题,我整理一下关于MySQL加锁和死锁的知识点,本来打算还要在放一个案例,但是感觉字数还是控制一下。不要把文章写的又臭又长,我在写这个文章的时候也借鉴了很多大佬的博客,学到很多知识,希望能给有问题的你提供一些思路。
杂记
MySQL中show指令的使用
show tables或show tables from database_name; – 显示当前数据库中所有表的名称。
show databases; – 显示mysql中所有数据库的名称。
show columns from table_name from database_name; 或show columns from database_name.table_name; – 显示表中列名称。
show grants for user_name; – 显示一个用户的权限,显示结果类似于grant 命令。
.show index from table_name; – 显示表的索引。
show status; – 显示一些系统特定资源的信息,例如,正在运行的线程数量。
show variables; – 显示系统变量的名称和值。
show processlist; – 显示系统中正在运行的所有进程,也就是当前正在执行的查询。大多数用户可以查看他们自己的进程,但是如果他们拥有process权限,就可以查看所有人的进程,包括密码。
show table status; – 显示当前使用或者指定的database中的每个表的信息。信息包括表类型和表的最新更新时间。
show privileges; – 显示服务器所支持的不同权限。
show create database database_name; – 显示create database 语句是否能够创建指定的数据库。
show create table table_name; – 显示create database 语句是否能够创建指定的数据库。
show engines; – 显示安装以后可用的存储引擎和默认引擎。
show innodb status; – 显示innoDB存储引擎的状态。
show logs; – 显示BDB存储引擎的日志。
show warnings; – 显示最后一个执行的语句所产生的错误、警告和通知。
show errors; – 只显示最后一个执行语句所产生的错误。
show [storage] engines; –显示安装后的可用存储引擎和默认引擎。




