HTTP协议浅谈
什么是HTTP协议
HTTP协议我想大家应该都不陌生,在这个互联网高度发达的今天。如果你不知道什么是HTTP协议那就有点Out了。HTTP协议(Hypertext transfer protocol)翻译成中文叫超文本传输协议。(从名字上能看出来他传输的不仅仅是文本)。HTTP是互联网的数据通信的基础。
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
HTTP协议是蒂姆·伯纳斯-李于1989年在欧洲核子研究组织发起的。真正第一Http协议版本是在1991年的发布的。HTTP协议已经走了20多年的经历。中间也有过好多版本的变化。
HTTP协议是应用层协议,他是基于TCP/IP协议去实现的,主要用户客户端和服务端的传递标准,默认端口是80。HTTP 是无连接无状态的协议。
HTTP/0.9版本
HTTP 0.9版本是最老的HTTP版本。HTTP 0.9版本的协议简单到极点,请求时,不支持请求头,只支持 GET 方法。客户端与服务器端的交互方式是request-respnose这种一次请求一次回答方式。而且每一个请求(HTTP链接)都要创建一次TCP链接,开销很大,打开页面很慢。而且当时也只能传输HTML文件。不可以传输其他文件,比较单一。
HTTP/1.0
HTTP 1.0是1996发布的。主要解决的是HTTP 0.9版本,内容不丰富的问题。在HTTP 1.0中可以传输,图片,文字,视频,音频,二进制文件(根据Content-type),这使得后续互联网发展有了更多内容。
HTTP 1.0 协议,除了丰富内容,还增加了POST和Head方法。而且HTTP 中还曾加了Header信息(Request和Response中都有Header信息)。在Header中可以存储一些与业务无关的信息,比如Content-Type内容类型。
HTTP 1.0 在Request和Response中怎加了HTTP协议的版本号。增加了HTTP Status Code 标识相关的状态码(200,404,502,304)等等。
从HTTP 1.0我们能看到对0.9版本做了很大的提升,首先是内容的增加,然后将请求内容和返回内容,分成了Head和Body,将业务信息存放到Body里面。将公共与业务无关的存放到Head中去。通过HTTP 协议的版本和HTTP status Code 可以让请求双方以及第三方的监控或管理程序有了统一的认识。最关键是还是控制错误和业务错误的分离。
HTTP 1.0 没有解决的问题是一个HTTP链接还是要创建一个TCP链接(每次都要3次握手,4次挥手)而且是串行请求,可能在那个对性能要求不高的年代是够用的。
Content-Type
1 | //常见的Content-Type |
这些数据类型总称为MIME type,每个值包括一级类型和二级类型,之间用斜杠分隔。MIME type还可以在尾部使用分号,添加参数。
1 | Content-Type: text/html; charset=utf-8 |
客户端请求的时候,可以使用Accept字段声明自己可以接受哪些数据格式。
1 | Accept: */* |
Content-Encoding
由于发送的数据可以是任何格式,因此可以把数据压缩后再发送。Content-Encoding字段说明数据的压缩方法。
1 | Content-Encoding: gzip |
客户端在请求时,用Accept-Encoding字段说明自己可以接受哪些压缩方法。
1 | Accept-Encoding: gzip, deflate |
请求与返回格式。这个时候一个HTTP 请求和响应分为三个部分:状态行、消息头、消息主体
1 | //请求格式(request) |
HTTP/1.1
HTTP 1.1的出现主要是解决网络的性能问题,后面也解决了安全问题。(HTTP 1.1应该分两个时代)
HTTP 1.1最重要的是TCP链接的复用,可以设置 keepalive 来让HTTP重用TCP链接,重用TCP链接可以省了每次请求都要在广域网上进行的TCP的三次握手的巨大开销。这是所谓的“HTTP 长链接” 或是 “请求响应式的HTTP 持久链接”。英文叫 HTTP Persistent connection.
支持HTTP pipeline(管线化)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。(注:非幂等的POST 方法或是有依赖的请求是不能被pipeline化的)
协议头注增加了 Language, Encoding, Type, Cache-control 等等头,让客户端可以跟服务器端进行更多的协商。Cache-control是服务器与客户端约定缓存时间。
还正式加入了一个很重要的头—— HOST这样的话,服务器就知道你要请求哪个网站了。因为可以有多个域名解析到同一个IP上,要区分用户是请求的哪个域名,就需要在HTTP的协议中加入域名的信息,而不是被DNS转换过的IP信息。为后面服务器虚拟主机兴起打下了基础。
正式加入了 OPTIONS PUT、PATCH、 DELETE 方法,OPTIONS 其主要用于 CORS – Cross Origin Resource Sharing应用(跨域)。
后面有出现HTTPS协议,也就是HTTP+TSL/SSL的协议,是一种在加密信道进行 HTTP 内容传输的协议。。在HTTP传输业务数据之前加入了TSL握手,证书。
HTTP 1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为“队头堵塞”(Head-of-line blocking)。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
keep-alive
在 HTTP 1.0 版本中,并没有官方的标准来规定 Keep-Alive 如何工作,因此实际上它是被附加到 HTTP 1.0协议上,如果客户端浏览器支持 Keep-Alive ,那么就在HTTP请求头中添加一个字段 Connection: Keep-Alive,当服务器收到附带有 Connection: Keep-Alive 的请求时,它也会在响应头中添加一个同样的字段来使用 Keep-Alive 。这样一来,客户端和服务器之间的HTTP连接就会被保持,不会断开(超过 Keep-Alive 规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 “Connection: close” 才关闭。目前大部分浏览器都使用 HTTP 1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况
HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。
HTTP 长连接不可能一直保持,例如
Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。HTTP 是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive 没能改变这个结果。另外,Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在 HTTP1.1 版本中也如此。唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于 Keep-Alive 的保持连接特性,否则会有意想不到的后果。
使用长连接之后,客户端、服务端怎么知道本次传输结束呢?两部分:1. 判断传输数据是否达到了Content-Length 指示的大小;2. 动态生成的文件没有 Content-Length ,它是分块传输(chunked),这时候就要根据 chunked 编码来判断,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束
目前,对于同一个域名,大多数浏览器允许同时建立6个持久连接。
HTTP Pipeline
HTTP 1.0情况下 HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。在使用持久连接的情况下,某个连接上消息的传递类似于请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3。
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似这样请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3。
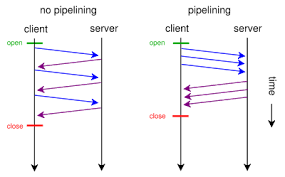
- 管线化机制通过持久连接(persistent connection)完成,仅 HTTP/1.1 支持此技术(HTTP/1.0不支持)
- 只有 GET 和 HEAD 请求可以进行管线化,而 POST 则有所限制
- 初次创建连接时不应启动管线机制,因为对方(服务器)不一定支持 HTTP/1.1 版本的协议
- 管线化不会影响响应到来的顺序,如上面的例子所示,响应返回的顺序并未改变
- HTTP /1.1 要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败即可
- 由于上面提到的服务器端问题,开启管线化很可能并不会带来大幅度的性能提升,而且很多服务器端和代理程序对管线化的支持并不好,因此现代浏览器如 Chrome 和 Firefox 默认并未开启管线化支持
Transfer-Encoding (分块传输编码 )
Transfer-Encoding 是一个用来标示 HTTP 报文传输格式的头部值。尽管这个取值理论上可以有很多,但是当前的 HTTP 规范里实际上只定义了一种传输取值——chunked。
Chunked Responses ,也就是说,在Response的时候,不必说明 Content-Length 这样,客户端就不能断连接,直到收到服务端的EOF标识。这种技术又叫 “服务端Push模型”,或是 “服务端Push式的HTTP 持久链接”。
Transfer-Encoding消息头的值为chunked,那么,消息体由数量未定的块组成,并以最后一个大小为0的块为结束。
每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)。
最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。消息最后以CRLF结尾。(EOF标识)
chunked 和 multipart 两个名词在意义上有类似的地方,不过在 HTTP 协议当中这两个概念则不是一个类别的。multipart 是一种 Content-Type,标示 HTTP 报文内容的类型,而 chunked 是一种传输格式,标示报头将以何种方式进行传输。(multipart 多用于文件上传)
chunked 传输不能事先知道内容的长度,只能靠最后的空 chunk 块来判断,因此对于下载请求来说,是没有办法实现进度的。在浏览器和下载工具中,偶尔我们也会看到有些文件是看不到下载进度的,即采用 chunked 方式进行下载。
chunked 传输不能事先知道内容的长度,只能靠最后的空 chunk 块来判断,因此对于下载请求来说,是没有办法实现进度的。在浏览器和下载工具中,偶尔我们也会看到有些文件是看不到下载进度的,即采用 chunked 方式进行下载。
chunked 的优势在于,服务器端可以边生成内容边发送,无需事先生成全部的内容。HTTP/2 不支持 Transfer-Encoding: chunked,因为 HTTP/2 有自己的 streaming 传输方式(Source:MDN - Transfer-Encoding)。
1 | // Chunked Response示例 |
HTTPS 基本过程
- 客户端发送一个
ClientHello消息到服务器端,消息中同时包含了它的 Transport Layer Security (TLS) 版本,可用的加密算法和压缩算法。 - 服务器端向客户端返回一个
ServerHello消息,消息中包含了服务器端的 TLS 版本,服务器所选择的加密和压缩算法,以及数字证书认证机构(Certificate Authority,缩写 CA)签发的服务器公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥。证书中还包含了该证书所应用的域名范围(Common Name,简称 CN),用于客户端验证身份。 - 客户端根据自己的信任 CA 列表,验证服务器端的证书是否可信。如果认为可信(具体的验证过程在下一节讲解),客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥
- 服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥
- 客户端发送一个
Finished消息给服务器端,使用对称密钥加密这次通讯的一个散列值 - 服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个
Finished消息,也使用协商好的对称密钥加密 - 从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容
从上面的过程可以看到,TLS 的完整过程需要三个算法(协议),密钥交互算法,对称加密算法,和消息认证算法(TLS 的传输会使用 MAC(message authentication code) 进行完整性检查)。
我们以 Github 网站使用的 TLS 为例,使用浏览器可以看到它使用的加密为 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256。其中密钥交互算法是 ECDHE_RSA,对称加密算法是 AES_128_GCM,消息认证(MAC)算法为 SHA256。
HTTP/2
目前HTTP 1.1协议也是大家用的最多协议。但是HTTP 1.1也有很多问题。尽管HTTP 1.1实现了TCP链接复用,但是HTTP中的数据传输依旧是串行,导致一个请求延迟导致其他请求也会跟着延迟(队头阻塞)。如果能把这个请求从串行改成并行会大幅提高效率,提高网络的吞吐率
从HTTP 0.9到HTTP 1.1 HTTP都使用的是文本形式传输,尽管使用CPU可以对内容进行gzip进行压缩(压缩,解压缩)提高网络带宽使用率,但是对客户端和服务端CPU性能使用大。所有对数据传输传输成本较大。不如RPC类协议的成本低。
2009年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。后面HTTP 2很多都是基于SPDY协议去做的。
2015年,发布了HTTP 2 它不叫 HTTP/2.0,是因为标准委员会不打算再发布子版本了,下一个新版本将是 HTTP/3。
二进制协议
HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。而且二进制可以大幅度提高传输的效率。
并发请求
HTTP/2是可以在一个TCP链接中并发请求多个HTTP请求,(在一个连接里,客户端和浏览器都可以同时发送多个请求或回应),而且不用按照顺序一一对应。移除了HTTP/1.1中的串行请求。
头信息压缩
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。这就是所谓的HPACK算法。
服务端push
HTTP/2允许服务端在客户端放cache,又叫服务端push,也就是说,你没有请求的东西,我服务端可以先送给你放在你的本地缓存中。比如,你请求X,我服务端知道X依赖于Y,虽然你没有的请求Y,但我把把Y跟着X的请求一起返回客户端。
HTTP/3
HTTP 2也是有问题。因为HTTP是服务层协议,不用考虑底层包传输。底层的报文传输时TCP去做的,由于我们复用了一个TCP链接就会有问题。我们都知道TCP协议是传输数据可靠的协议(基于三次握手。建立序列号,然后丢包重传机制等等)。由于网络原因可能导致TCP丢包,那么在重传的时候会把整个链接传输性能下降,也就是重传,(一旦发生丢包,造成的问题就是所有的HTTP请求都必需等待这个丢了的包被重传回来,哪怕丢的那个包不是我这个HTTP请求的)。所以在弱网的情况下,TCP协议应该是不可以了,因为他的重传机制导致,性能下降。所以在HTTP/3中,使用UDP协议代替TCP协议。因为UDP没有序列号,同时也没有那么大的TCP头。
QUIC (Quick UDP Internet Connections)协议。QUIC是一个在UDP之上的伪TCP +TLS +HTTP/2的多路复用的协议。
UDP协议代替TCP协议的挑战
比如在NAT的环境下,如果是TCP的话,NAT路由或是代理服务器,可以通过记录TCP的四元组(源地址、源端口,目标地址,目标端口)来做连接映射的,然而,在UDP的情况下不行了。于是,QUIC引入了个叫connection id的不透明的ID来标识一个链接,用这种业务ID很爽的一个事是,如果你从你的3G/4G的网络切到WiFi网络(或是反过来),你的链接不会断,因为我们用的是connection id,而不是四元组。
引用了connection id,也还是会有问题 ,比如一些不够“聪明”的等价路由交换机,这些交换机会通过四元组来做hash把你的请求的IP转到后端的实际的服务器上,然而,他们不懂connection id,只懂四元组,这么导致属于同一个connection id但是四元组不同的网络包就转到了不同的服务器上,这就是导致数据不能传到同一台服务器上,数据不完整,链接只能断了。所以,你需要更聪明的算法。
HTTP/2的头压缩算法 HPACK,HPACK需要维护一个动态的字典表来分析请求的头中哪些是重复的,HPACK的这个数据结构需要在encoder和decoder端同步这个东西。在TCP上,这种同步是透明的,然而在UDP上这个事不好干了。所以,这个事也必需要重新设计了,基于QUIC的QPACK就出来了,利用两个附加的QUIC steam,一个用来发送这个字典表的更新给对方,另一个用来ack对方发过来的update。
总结
随着网络世界的复杂化,我们对原有的网络设施的基础要求也会越来越高。从TCP多链接链接GET请求的HTTP/0.9,在到并行的复用TCP链接的HTTP/2。我们对网络要求质量越来越高,协议也越来越复杂。我们每解决一个问题都会有新的问题出现,这也是不断推动这我们进步的过程(同时程序员学习的成本和门槛也越来越高)。不过未来还是很期待HTTP/3,使用UDP取代TCP。TCP是否会成为历史,未来to be continued。。。。






