浅谈JMM
前言
我们知道Java是一个跨平台的语言(毕竟一次编写处处异常不是白说的),我们知道Java在保证跨平台的时候使用了JVM来屏蔽了底层。同时它也有很多标准,这次我们就了解JMM(Java Memory Mode) Java内存模型。
JMM模型
JVM内部使用的Java内存模型在线程堆栈和堆之间分配内存。从简单逻辑上就只有栈和队,但是实际上比这个复杂。
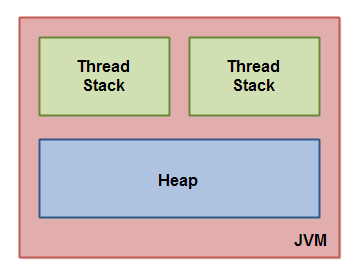
Java虚拟机中运行的每个线程都有其自己的线程堆栈。线程堆栈包含有关线程调用了哪些方法以达到当前执行点的信息。我将其称为“调用堆栈”。当线程执行其代码时,调用堆栈会更改。(程序计数器 Program Count Register)
线程堆栈还包含正在执行的每个方法(调用堆栈上的所有方法)的所有局部变量。线程只能访问自己的线程堆栈。由线程创建的局部变量对创建线程之外的所有其他线程不可见。即使两个线程执行的代码完全相同,这两个线程仍将在各自的线程堆栈中创建该代码的局部变量。因此,每个线程对每个局部变量都有其自己的版本。(虚拟机栈和本地方法栈)
基本类型的所有局部变量( boolean,byte,short,char,int,long, float,double)完全存储在线程栈上,因此不是其他线程可见。一个线程可以将一个主要变量的副本传递给另一个线程,但是它不能共享基本类型局部变量,他是线程私有的。(所以一般volatile都使用与原始的基本类型)
堆包含在Java应用程序中创建的所有对象,无论是那个线程创建的对象。这包括基本类型的包装类(例如对象的版本Byte,Integer,Long等等)。创建一个对象,把引用值赋给局部变量(引用),或者直接创建一个对象,(不需要引用的那种),这些对象都存储在堆上。
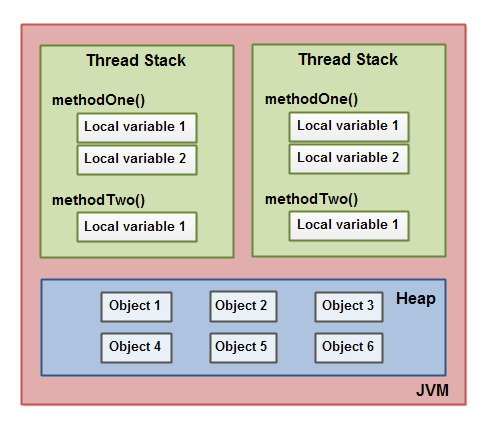
从图中我们可以看待线程本地存放了那些局部变量和方法调用位置。而堆中存放了具体的对象信息。除了基本类型的局部变量以外,栈上还存储了对象的引用,对象自己时存储在堆上面的。
一个对象可能包含方法,而这些方法可能包含局部变量。即使这些方法所属的对象存储在堆中,这些局部变量也存储在线程堆栈中。
对象的成员变量与对象本身一起存储在堆中。当成员变量是基本类型时,以及它是对对象的引用时,都是如此。
当然,对象也可以存储在栈上,如果改对象通过逃逸分析,分析没有逃逸,就可以对对象进行标量替换,将一个对象替换成局部变量。
静态类变量(static)也与类定义一起存储在堆中。
引用对象的所有线程都可以访问堆上的对象。当线程可以访问对象时,它也可以访问该对象的成员变量。如果两个线程同时在同一个对象上调用一个方法,则它们都将有权访问该对象的成员变量,但是每个线程将拥有自己的局部变量副本。(如果不存在加锁的条件下)
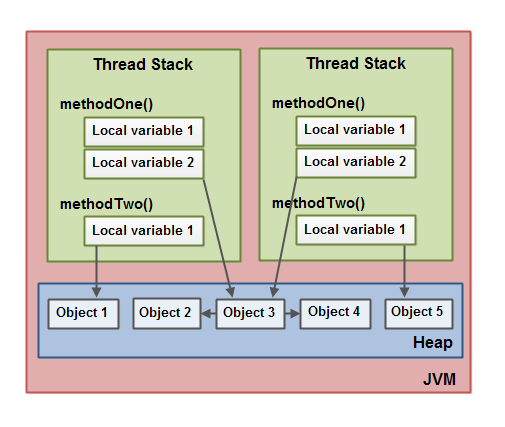
两个线程具有一组局部变量。这个局部变量(Local Variable 2,存储在栈上)指向堆上的共享对象(object3)。这两个线程有两个不同引用(引用也是局部变量)指向了堆上的同一个对象(object3)。它们的引用是局部变量,因此存储在每个线程的线程堆栈中(线程隔离的内存),他们是不同引用指向同一个对象。
共享对象(object3)引用(object2)和(object4)作为成员变量(由对象3到对象2和对象4的箭头所示)。通过对象3中的这些成员变量引用,两个线程可以访问(object3)和(object4)。
该图还显示了一个局部变量,该局部变量(Local Variable 1)指向堆上的两个不同对象。在这种情况下,引用指向两个不同的对象(object1和object5),而不是同一对象在堆上。理论上,两个线程都可以访问这两个对象(object1和object5)如果两个线程都引用了这两个对象(object1和object5)。但是在上图中,每个线程只引用了其中一个对象。
下面我们就用的代码去解释上面图片描述的内容
1 | public class MyRunnable implements Runnable() { |
1 | public class MySharedObject { |
如果有两个线程去执行run()方法,就会展示上面图中的情况。run()方法调用methodOne()方法,然后methodOne()方法调用methodTwo()方法。
methodOne()方法声明了一个基本类型局部变量(localVariable 1)类型是int型的。还有一个对象引用局部变量,是MySharedObject对象引用局部变量。(localVariable 2)
每个执行methodOne()方法的线程都是自己创建一份局部变量(localVariable 1)副本和局部变量(localVariable 2)副本到自己的线程栈中。局部变量(localVariable 1)将完全彼此分离,仅存在于每个线程的线程堆栈中。 一个线程看不到另一个线程对其localVariable 1副本所做的更改。
每个执行methodOne()的线程还将创建自己的(localVariable 2)副本。localVariable2的两个不同副本最终都指向堆上的同一对象(object3)。 代码将localVariable 2设置为指向静态变量引用的对象。 静态变量只有一个对象,并且存储在堆中。localVariable 2的两个副本最终都指向静态变量指向的MySharedObject的同一实例。 MySharedObject实例存储在堆中。 它对应于上图中的(object3)。
MySharedObject类也包含两个成员变量。成员变量本身与对象一起存储在堆中。这两个成员变量指向另外两个Integer对象。这些整数对象对应于上图中的object2和object4。
methodTwo()创建一个名为localVariable 1的局部变量。这个局部变量是Integer类型对象的引用。methodTwo()方法将localVariable 1引用设置为指向新的Integer实例。执行methodTwo()f方法的每个线程的localVariable 1引用将存储在线程栈上。由于该方法每次执行该方法时都会创建一个新的Integer对象,所以实例化的两个Integer对象将存储在堆中,执行methodTwo()方法的两个线程将创建单独的Integer实例。在methodTwo()内部创建的Integer对象对应于上图中的object1和objecct5。
MySharedObject类中类型为long的两个成员变量是基本类型。由于这些变量是成员变量,因此它们仍与对象一起存储在堆中。仅局部变量存储在线程堆栈上。member1和member2
现代计算机硬件架构
现代计算机都是冯诺一曼机。都是由内存,计算器,控制器,输入输出设备构成。计算器和控制器合成了CPU,内存就是我们常说的主内存,但是学过计算机组成原理的我们都知道由于CPU和主内存和CPU频率差距过大,就会在CPU和主内存中间会有高速缓存。

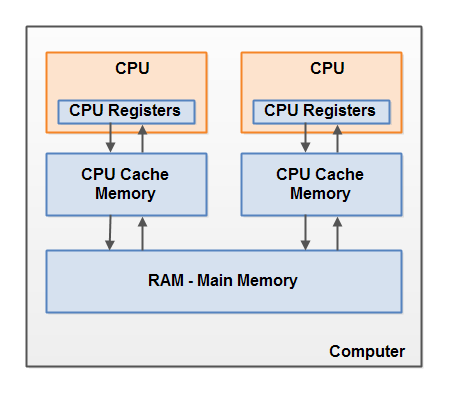
现代计算机一般都是多个CPU,例如上面就是8核的处理器,每个CPU都可以在任何给定时间运行一个线程。这意味着,如果您的Java应用程序是多线程的,则每个CPU可能在Java应用程序中同时(并发)运行一个线程。
通常,当CPU需要访问主内存时,它将部分主内存读入其CPU缓存。它甚至可以将缓存的一部分读入其内部寄存器,然后对其执行操作。当CPU需要将结果写回主存储器时,它将把值从其内部寄存器刷新到高速缓存,然后在某个时候将值刷新回主存储器。
当CPU需要将其他内容存储在高速缓存中时,通常会将高速缓存中存储的值刷新回主存储器。CPU高速缓存可以一次将数据写入其部分内存,并一次刷新其部分内存。它不必每次更新都读取/写入完整的缓存。通常,缓存在称为“缓存行”的较小存储块中更新。可以将一个或多个高速缓存行读入高速缓存存储器,也可以将一个或多个高速缓存行再次刷新回主存储器。
从上面我们也能看出来,一些问题,就是JVM中内存大的管理和硬件系统的管理是一样,存在这巨大的差异。
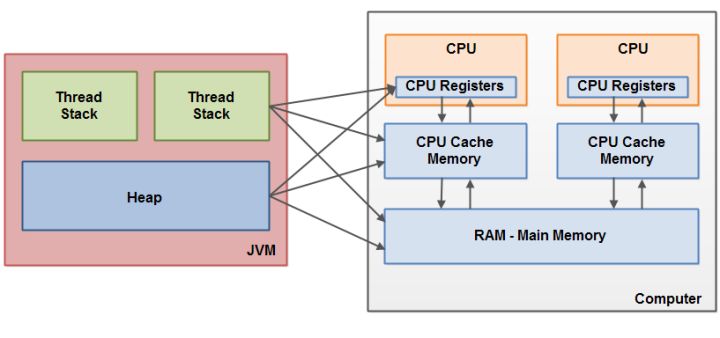
硬件内存体系结构不能区分线程堆栈和堆。在硬件上,线程堆栈和堆都位于主内存中。有时,部分线程堆栈和堆可能会出现在CPU缓存和内部CPU寄存器中。
当对象和变量可以存储在计算机的各种不同存储区域中时,可能会出现某些问题。两个主要问题是:
线程对共享变量的更新(写入)的可见性。
读取,检查和写入共享变量时的竞争条件。
共享变量的可见性
如果两个或者两个以上线程共享的变量,没有使用volatile关键字声明或者使用同步块(synchronized)。一个线程更新这个共享对象会让其他线程不可见。
想象一下,一开始这个共享对象存储在主内存,在CPU上的运行的一个线程将共享内存读到CPU自己的缓存中,在CPU缓存里改变了共享对象,这个时候CPU还没有刷新缓存到主内存。这个时候共享对象改变的的版本,对于运行在其他CPU上的线程是不可见的。这样就会导致每一个线程运行结束的时候将自己CPU缓存中的共享对象的副本刷新到主内存的时候会互相覆盖。同时这个写不同线程的共享对象的副本也是不一样的。
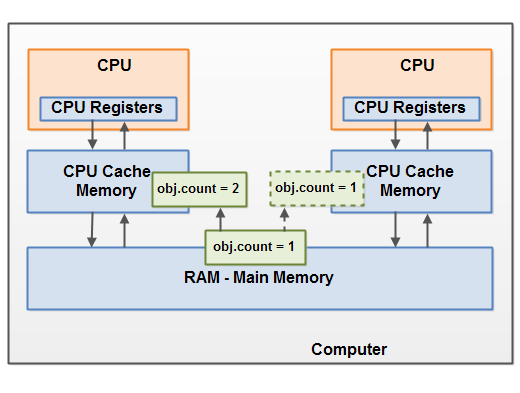
图中,左侧CPU上运行的一个线程将共享对象复制到CPU缓存中,并将其count变量修改成2,但是右侧CPU上运行的线程看不到这次更改。这样就会导致计数的错误。因为左侧CPU并没有将计数完的数据刷回到主内存,导致少计数了。
要解决此问题,可以使用Java的volatile关键字。 volatile关键字可以确保给定的变量直接从主存储器中读取,并在更新时始终写回到主存储器中。后面我们回详细结束volatile关键字的实现方法。
竞争条件
如果两个多这多喝线程共享一个对象,在多线程更新这个共享对象的变量的时候就会可能发生竞争条件。
想象一下,如果线程A读取共享对象中的count计数变量,线程B也读取了共享对象的count变量,但是他们是存在不同的CPU缓存上的。现在线程A堆count加1,线程B也堆count加1.现在count变量已经增加了两次,在每个CPU的缓存里。
如果这些增加时顺序执行的,那么共享对象的count变量增加两次,那么最后会将原始值+2,刷新主内存里,但是这个两个加1操作没有进行适当的同步(使用锁)的情况下同时执行。无论线程A还是线程B那个更新写回主内存,最后的值都原始值+1。
该图说明了如上所述的竞争条件问题的发生
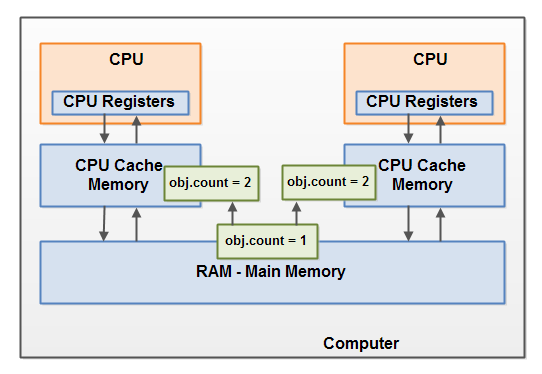
要解决此问题,可以使用Java synchronized 同步块。 synchronized 同步块可确保在任何给定时间只有一个线程可以执行synchronized同步块内的代码。 synchronized 同步块还保证从同步块中读取的所有变量都将从主存储器中读取,并且当线程退出synchronized同步块时,所有更新的变量将再次刷新回主存储器,而不管该变量是不是声明为volatile。(synchronized同步块更多时候时锁,而且时个可重入的锁)
杂记
逃逸分析:逃逸分析的基本原理是,分析对象的作用域,当一个对象在方法里被定义后,它可能被外部的方法引用(对象是当前方法的返回值,作为调用参数被传递到其他方法上)这种叫方法逃逸。甚至有可能被其他外部线程访问到(对象的静态变量,赋值给其他线程的实例变量)这种叫线程逃逸。
在方法内使用,不被外部方法调用或者引用(不逃逸)。被外部方法引用(方法逃逸)。被外部线程引用(线程逃逸),针对不同的逃逸级别,JVM会做不同的优化。
标量替换:如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
栈上分配:如果能够通过逃逸分析确定某些对象不会逃出方法之外,那就可以让这个对象在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
上面这些内容在之前的博客也有过,浅谈Java垃圾回收与JVM。详细了解的可以去看一下之前的
本来打算把volatile关键字也写上的,我怕篇幅过长,就只是翻译了上面的文章,加了自己的一点见解。后面我会写关于volatile关键字详细的内容。了解了JMM对后面理解多线程,有更好的帮助。








