浅谈Redis底层-SDS
前言
Redis我想大家都很熟悉,我们都会用Redis去做缓存。Redis常用的数据结构大家也都熟悉,Redis常用数据结构我想大家也都知道,除了最常用的String,List,Set,Hash,Zset,BitMap,HyperLogLog,Geo等等。之前我写过Redis基本数据结构的文章。不过Redis真正怎么通过C语言的程序设计去让这个Redis更快,更加高性能。可以简单的研究一下关于Redis底层的数据结构。
SDS
SDS:(simple dynamic string)简单的动态字符串。动态字符串是一种由Redis提供的字符串的数据结构,他不是使用C语言自带的字符串。(C语言自带的字符串还是由一些问题,比如内存溢出,查找字符串的长度等等)。
SDS的简单定义
1 | typedef char *sds |
这个是Redis 3.2版本时SDS的数据结构。我们可以与C语言原有的字符串数据结构进行对比,如何提高Redis的性能。
如果在C语言中存储一个字符串是这样的。
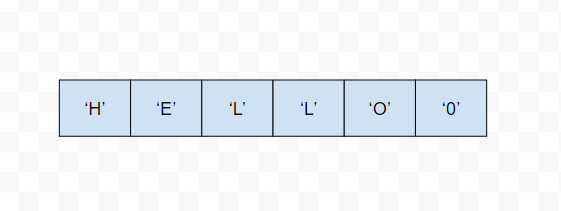
在SDS中是这样的

其实buf中存储的就是字符串数据,而且还剩余了一部分空间。而且还存储了字符串长度和剩余空间的大小。使用的空间明显比之前的大了。但是他的一些效率也提升了。(用空间去换时间)
下面就简单说一下Redis使用这种数据结构的好处相比C语言的char*。
1、提高了查找字符串长度时间。
原有C语言的是没存字符串长度的,每次获取字符串长度都要遍历一下字符数组。这个时间复杂度是O(n),但是在SDS中记录了字符串长度。时间复杂度O(1)。这里的len不会计算”\0”所占用的空间(与C语言保持一致)
2、避免内存缓存区溢出。
缓存区溢出:C语言是一个没有边界检查的语言,向程序输入缓冲区写入使之溢出的内容(通常是超过缓冲区能保存的最大数据量的数据),从而破坏程序运行、趁著中断之际并获取程序乃至系统的控制权。
简单点说就是原来能存10个byte,然后存了20byte。溢出到别的内存中,影响运行时数据。简单举一个栗子
原有相邻两个字符串,s1= hello和s2 = world。

在s1后面追加数据,Redis。应该申请足够的空间,拼接字符串strcat(s1, “ REDIS”);。如果忘记申请空间直接拼接就会有缓存区溢出,会把原来的world覆盖。不过C语言也会有安全的方法如strlcat()。

Redis 中SDS 的空间分配策略完全杜绝了发生缓冲区溢出的可能性, 当我们需要对一个SDS 进行修改的时候,redis 会在执行拼接操作之前,预先检查给定SDS 空间是否足够,如果不够,会先拓展SDS 的空间,然后再执行拼接操作。
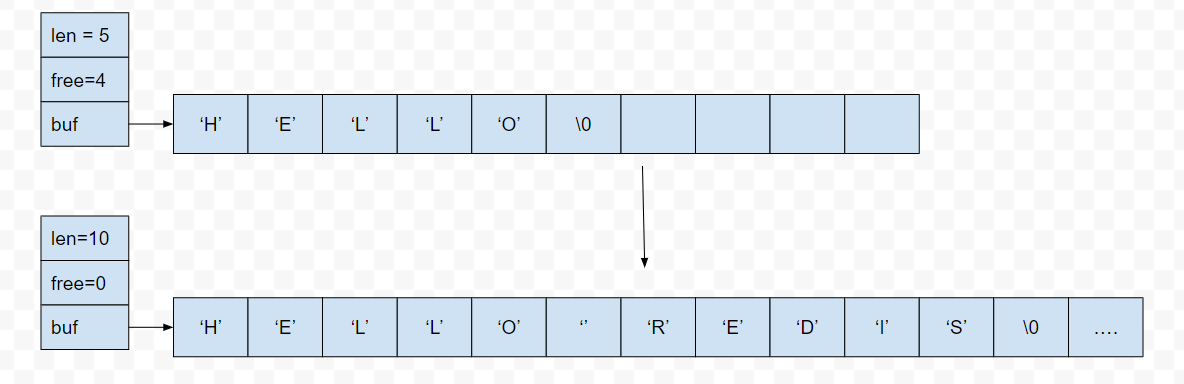
对于SDS而言,作者专门封装了一个类似于strcat的方法:sdscatlen,作用正是对SDS进行字符串拼接。
1 | /* sds.c: line 386 */ |
SDS在长度发生变化时,会自动检测是否需要进行扩容,这就规避了上文示例中缓冲区溢出的风险。这便是SDS的一大特点:可自主扩容,不需要使用者关心空间的申请。在上面的代码中,有一个比较重要的函数:sdsMakeRoomFor()。
1 | /* sds.c: line 197 */ |
这里规定了SDS的扩容规则:如果新字符串长度小于1M,申请双倍空间,如果新字符串长度大于1M,则只会多申请1M。
SDS 创建函数
1 | * sds.c: line 84 */ |
3、减少修改字符串时带来的内存重分配次数
C语言字符串在进行字符串的扩充和收缩的时候,都会面临着内存空间的重新分配问题。
字符串拼接会产生字符串的内存空间的扩充,在拼接的过程中,原来的字符串的大小很可能小于拼接后的字符串的大小,那么这样的话,就会导致一旦忘记申请分配空间,就会导致内存缓冲区的溢出。
字符串在进行收缩的时候,内存空间会相应的收缩,而如果在进行字符串的切割的时候,没有对内存的空间进行一个重新分配,那么这部分多出来的空间就成为了内存泄露(无法被回收)。
同时C语言对字符串修改时会内存操作。也就是申请和释放掉无用的内存,上面也说了防止缓冲区溢出和内存泄漏。所以会用到malloc,realloc,calloc函数去申请内存。(一般malloc和free一定要一起使用)否则会内存泄漏
malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表的功能。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。如果无法获得符合要求的内存块,malloc函数会返回NULL 指针,因此在调用malloc动态申请内存块时,一定要进行返回值的判断。
malloc是一个比较复杂的过程,所以通过SDS可以提前给字符一些多余的空间。通过free字段记录。避免每次增长字符串时区申请空间。或者释放空间,释放空间有统一的释放。
4、惰性空间释放
我们在观察SDS 的结构的时候可以看到里面的free 属性,是用于记录空余空间的。我们除了在拓展字符串的时候会使用到free 来进行记录空余空间以外,在对字符串进行收缩的时候,我们也可以使用free 属性来进行记录剩余空间,这样做的好处就是避免下次对字符串进行再次修改的时候,需要对字符串的空间进行拓展。
然而,我们并不是说不能释放SDS 中空余的空间,SDS 提供了相应的API,让我们可以在有需要的时候,自行释放SDS 的空余空间。sdsRemoveFreeSpace,支持手动对SDS的空闲空间进行清理,不过这个函数只会保留已用的空间,会将所有未用的空间都给释放掉
通过惰性空间释放,SDS 避免了缩短字符串时所需的内存重分配操作,并未将来可能有的增长操作提供了优化。
5、二进制数据更加友好
C语言中存储字符串
C 字符串中的字符必须符合某种编码,并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存想图片,音频,视频,压缩文件这样的二进制数据。
但是在Redis中,不是靠空字符来判断字符串的结束的,而是通过len这个属性。那么,即便是中间出现了空字符对于SDS来说,读取该字符仍然是可以的。
虽然SDS 的API 都是二进制安全的,但他们一样遵循C字符串以空字符串结尾的惯例。所以对C语言原有的字符串也时友好的。
SDS的升级
在redis3.2,对SDS做过比较大的改版,主要就在于对于不同长度的字符串,使用不同的数据结构。这个定义在sds.h的文件中声明。而且原来的free也变成了alloc。
sds.h的代码
1 | /* Note: sdshdr5 is never used, we just access the flags byte directly. |
可以看到,新版本要求针对不同长度的字符串,选用不同的struct。而各个struct的区别就在于,len和alloc的类型不一样。其中,uint8_t占用1个字节(8 bit),uint16_t占用2个字节(16 bit),uint32_t占用4个字节(32 bit),uint64_t(64 bit)占用8个字节。而旧版本中统一使用的int占用4个字节(32位机器和64位机器都是4个字节)。uint8_t,uint16_t,uint32_t等都不是什么新的数据类型,它们只是使用typedef给类型起的别名。不过,不要小看了typedef,它对于你代码的维护会有很好的作用。
SDS 一般是采用了一段连续的内存空间来存储动态字符串 header (len / alloc / flags) + buf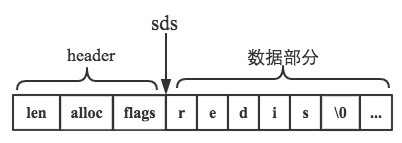
__attribute__ ((__packed__))要求编译器取消字节对齐,防止编译器的 C 内存对其原则优化,否则经过优化就不能保证 header 和 buf数据部分 是紧紧相邻 的内存空间了。所以现在 获取 flag 的值可以直接往前便宜1个字节即可:unsigned char flags = s[-1]。
杂记
内存对齐原则
对于CPU而言,每次从内存中存取数据都需要一定的开销。为了减少存取次数,CPU每次总会以2/4/8/16/32字节为单位进行存取操作。这个存取单位就叫做内存存取粒度。
为了迎合CPU的这种存取机制,应用程序应该尽可能相关联的数据所占用的数据块儿大小,刚好是存取单位字节数的整数倍,这样才能够保证CPU的存取次数最小






