浅入浅出RocketMQ
前言
MQ (Message queue) 即消息队列,简单来说就是你发送一个消息向队列里面,然后订阅这个队列的系统就会收到消息信息,内容就和你发出去的一样。这样的产品有很多比如RocketMQ,Kafka,ActiveMQ和RabbitMQ等等。使用MQ的主要作用就是解耦。举个例子,比如你的订单流程特别长,包括下单,支付,库存扣减,消息推送,发货,积分,优惠券,大数据同步等等,涉及好多系统。这些系统肯定都是相对独立的,如果把所有功能都做到一个系统肯定会把人作死。所以我们会使用分布式调用的方式去实现,但是后来你发现通过分布式这种同步调用会导致整个下单流程很长,而且时间也很长经常超时,特别是在一些活动的时候压力上来了订单系统创建时间更长了。为了解决这个问题我们帮同步的调用改成异步的调用就引用了MQ。(当然这只是举了一个例子)
RocketMQ是什么,他是由哪几部分组成的
RocketMQ是一个分布式消息和流数据平台,具有低延迟、高性能、高可靠性、万亿级容量和灵活的可扩展性。RocketMQ是2012年阿里巴巴开源的第三代分布式消息中间件,2016年11月21日,阿里巴巴向Apache软件基金会捐赠了RocketMQ;第二年2月20日,Apache软件基金会宣布Apache RocketMQ成为顶级项目。
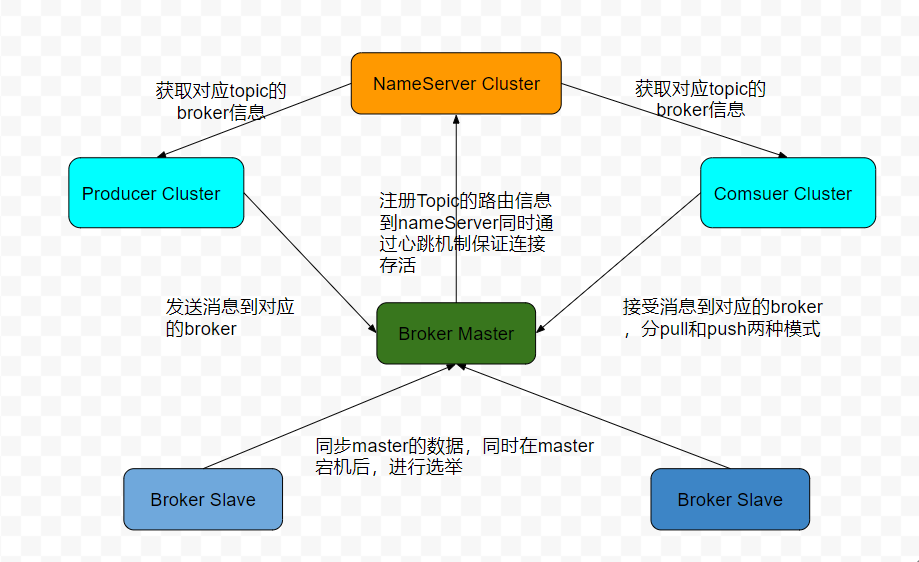
RocketMQ由四部分组成:命名服务器(Name Server)、代理(Broker)、生产者(Producer)和消费者(Consumer),其中每一个都可以水平扩展而没有单点故障。他们大致的通信方式如下图。
RocketMQ为什么这么设计,它那四部分都是干什么的
RocketMQ架构图
从RocketMQ的架构图上看,我们能看出来Rocke每个Broker都是不是单点,存在Master和slave这种HA模式,提高了MQ的可用性,增加了NameServer集群增加对集群的控制和管理使MQ的扩展容量达到万亿级别,同时也增加集群的可靠性。
Producer和Consumer
producer(生产者)生产消息的一端,将消息传递给Broker,不过它要获取Broker信息先通过NameServer获取对应Topic的Borker信息然后建立一个长连接,然后发送消息。
consumer(消费者)消费信息的一段,从broker获取消息,它也需要从NameServer获取对应Topic的Broker信息然后建立一个长连接,然后从broker拉去信息,一般分push和poll两种模式。
NameServer
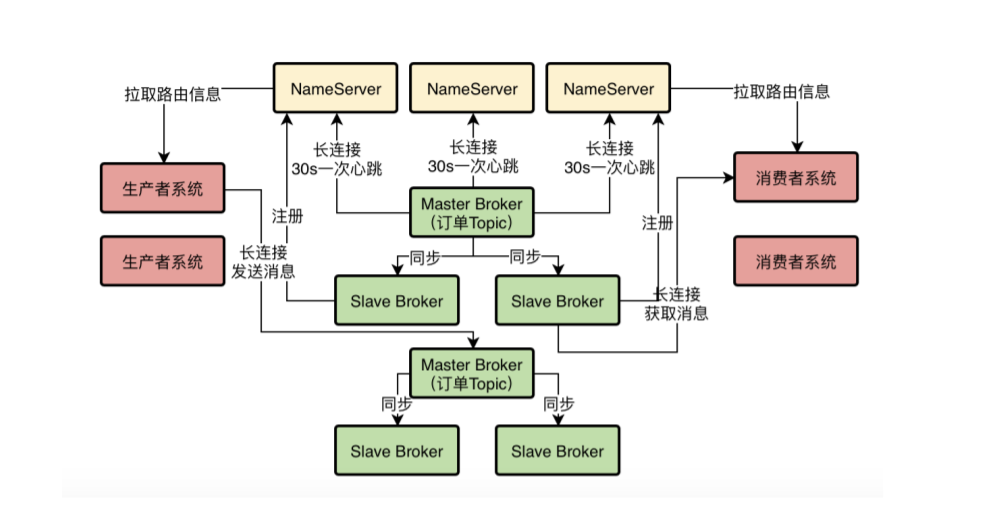
NameServer就像管理集群的注册中心,你仔细去看整个RocketMQ的集群也很向dubbo和SpringCloud的集群。NameServer也像Zookeeper和Eureka一样,管里Borker,producer和consumer(dubbo只有provider和consumer)不过NameServer主要管理Broker。每次增加Broker都要把Topic和对应Broker信息注册到NameServer,然后Broker通过心跳机制去保证和NameServer联系。Broker每隔30秒去给NameServer注册心跳然后更新NameServer上的时间,同时NameServer每隔10秒去清理那些是失去连接的Broker来保证整个集群的可用性,不会出现分区。
Broker
broker是MQ集群的重点,因为它负责消息的存储和分发,简单说就是Producer把生产消息存放到broker上存储,然后consumer到broker上去pull/push一些数据。所以Broker要主要负责消息的存储和分发。如何保证海量数据不丢失存储同时保证在高并发下保证性能和可靠,这些都是通过broker实现的。
分布式存储+HA高可用集群保证Broker不会轻易宕机。所有消息不可能存储到一个broker节点,肯定是存在多个节点实现分布式存储(每一个broker都只有一部分消息,根据Topic去划分,实际上是根据MessageQueue区分)同时每个broker节点也不是单个运行而是由master-slave这种主从模式去实现高可用,通过DLedger算法实现宕机后的master选举。保证节点的可用。Producer和Consumer与Broker保持长连接,消息同步刷盘ACK回执,保证数据传输稳定。
一个消息使如何通过RocketMQ从Producer传输到Consumer
1、RocketMQ启动,Producer与NameServer创建长连接,Conusmer与NameServer创建长连接,NameServer与Broker创建长连接(Broker把自己与Topic信息注册到对应的NamseServer上)
2、创建Topic和对应的MessageQueue。(这个一般创建MQ前要申请的)
3、Producer创建message。(一般是在业务产生时候使用的,比如你创建一个订单15分钟延时MQ)
4、Producer从NameServer获取Topic信息与Broker创建长连接,发送信息给对应MessageQueue的Broker。(产生消息后,要将消息传给对应的Broker,然后有Broker去路由消息)
5、Broker消息持久化,Broker把消息存放在commitLog中。(commitLog是物理地址,MessageQueue存放commitLog中的偏移量offset),commitLog通过顺序IO和PageCache实现了高性能持久化。(同步刷盘,异步刷盘,同步刷盘有有持久化,异步刷盘数据应该在缓存里,这种如果停机会丢失数据)
6、将数据从Master节点同步到Slave节点,保证高可用。(有点类似与读写分离,但RocketMQ只有在Master处理不过来才会从Slave上拉数据)
7、Consumer通过NameServer获取对应Topic的Broker路由信息。(MQ启动就获取好,如果后台有添加会通知到对应Consumer在从新拉取)
8、Consumer从对应Broker对应Message上pull/push消费。返回消费成功回执(无论是pull/push都是Counsumer去Broker上拉消息,类似于定时任务,只不过push比pull实时性更好点)
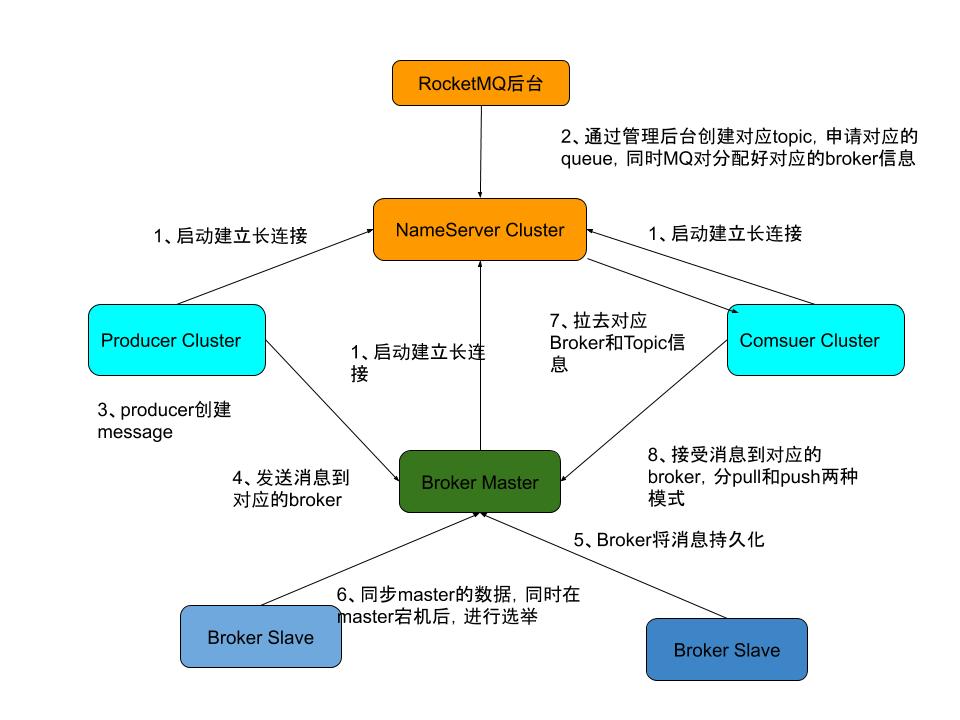
上面大致说了MQ从生产到消费的过程,不是完全准确,一般Consumer对Broker信息拉去都是定时去拉去的,不是在有消息的时候才会去找那个消息。而且消息都是Consumer去定时拉去的(定时比较短)。所以上面这8步步都是按照顺序来,我只是列了一个序号,有个大致的流程,才有了这个先后顺序。
总结
这里只是简单的描述和概况RocketMQ的工作原理的基本的架构和组成,没有涉及到对应的分布式事务和源代码级别的分析,连最简单的Demo也没有(想看demo自己去网上搜一下)。
RocketMQ总体上看就是一个分布式存储消息的集群。真正处理业务时Broker。而对应Producer和Consumer都是外部需要解耦的系统接进来的。然后通过NameServer统一管理,感觉和SpringCloud和Dubbo的这种集群也差不多,保证集群的高可用,高性能,高并发也差不多。
RokcetMQ主要就是做业务解耦,同时在一些秒杀,订单延时,数据同步中会用到。不过RokcetMQ只是解决问题中的一环,除了这个还要好多问题要解决。
MQ的选型也有很多,RocketMQ一般在业务上用的比较多,支持延时消息,事务消息,保证消息不丢失的重发机制。如果在大数据量同步上还是Kafka这种吞吐量好一点,Kafka也可以不丢数据(实现策略相对复杂)。各有利弊根据自己的业务去选型,实现最优解。鄙人才疏学浅就先扯到这里把








