什么是ElasticSearch Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。
简单来说ES是一个搜索引擎,通过URI Search API和 DSL Search API 两种搜索方式,它的底层数据结构是倒排索引,实现快速搜索。
ElasticSearch 一般存储的是非机构化的数据,简单来说就是JSON。它可以根据JSON内容自动生成索引(index),针对自动生成索引也可以使用index template 自动生成对应的mapping,也可以自己创建索引在导入数据。(我们一般在生产上都是先指定索引在导入数据)。
ES中的一些名词解释 索引(index) :ES中索引是文档的容器,是一类文档的结合,Index体现了逻辑空间的概念,每个索引都有自己的mapping的定义。用于定义包含文档的字段名和字段类型。
查看索引的对应的DSL 语句
1 2 3 4 5 6 7 8 9 10 GET /_cat/indices green open kibana_sample_data_ecommerce 56ybxw24QKSG_pBjqsd7Gg 1 0 4675 0 4.9mb 4.9mb green open kibana_sample_data_flights J_7ex02RTYqyzDak6plTXg 1 0 13059 0 6.4mb 6.4mb GET _cat/indices?v health status index uuid pri rep docs.count green open kibana_sample_data_flights J_7ex02RTYqyzDak6plTXg 1 0 13059 green open kibana_sample_data_ecommerce 56ybxw24QKSG_pBjqsd7Gg 1 0 467
类型(type) :ES中的type只是基本字段,当您执行 GET /my_index/my_type/_search 时,t将为字段 _type 的 my_type 值运行预过滤器 , type就像一个自动过滤器。不要将索引和类型视为 SQL 世界中的数据库和表。type在ES的版本升级中逐渐放弃使用。
Elasticsearch 5.6.0
通过对 index 设置参数 index.mapping.single_type: true 就能够启用单 index 单 type 限制(一个 index 只能支持一个 type),同样该限制从 6.0 版本开始该限制会强制启用。
Elasticsearch 6.x
在 Elasticsearch 6.x 中,一个 index 只能支持一个 type,推荐的 type 名字为 _doc(这样可以在 API 方面向后兼容 7.x )
在 Elasticsearch 6.8 中,Elasticsearch 引入了一个参数控制 type 开关:include_type_name,默认值为 true,表示仍使用 type,手动设置为 false 后,请求 es 的 API 将不再包含 type,而是使用类 PUT /{index}/_doc/{id} 的格式
Elasticsearch 7.x
在 Elasticsearch 7.x 中,include_type_name 被默认置为 false,新的 index API 格式为 PUT /{index}/_doc/{id} 和 POST {index}/_doc 。需要注意的是,_doc 并不是一个 type ,而仅仅是 API 请求路径中永久的一部分。手动创建索引不用指定type
Elasticsearch 8.x
在 Elasticsearch 8.x 中,include_type_name 已被删除,同时也表示 es 不再支持任何自定义 type 。
字段(field): ES中的字段类似MySQL数据库中的表字段(Colum),不过ES一个Filed支持多字段属性。我们在mapping中会看的更加明显
文档(Document) :文档是可以索引的基本信息单元。ES中的doc就是单条的数据,类似于MySQL上select语句返回的数据。单条订单信息或者单条的学生信息。
映射(mapping): ES中的mapping主要存储对应字段的定义,类似表结构(建表SQL)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 GET kibana_sample_data_flights/_mapping { "kibana_sample_data_flights" : { "mappings" : { "properties" : { "AvgTicketPrice" : { "type" : "float" }, "Cancelled" : { "type" : "boolean" }, "Carrier" : { "type" : "keyword" }, "Dest" : { "type" : "keyword" }, "DestAirportID" : { "type" : "keyword" }, "DestCityName" : { "type" : "keyword" }, "DestCountry" : { "type" : "keyword" }, "DestLocation" : { "type" : "geo_point" }, "DestRegion" : { "type" : "keyword" }, "DestWeather" : { "type" : "keyword" }, "DistanceKilometers" : { "type" : "float" }, "DistanceMiles" : { "type" : "float" }, "FlightDelay" : { "type" : "boolean" }, "FlightDelayMin" : { "type" : "integer" }, "FlightDelayType" : { "type" : "keyword" }, "FlightNum" : { "type" : "keyword" }, "FlightTimeHour" : { "type" : "keyword" }, "FlightTimeMin" : { "type" : "float" }, "Origin" : { "type" : "keyword" }, "OriginAirportID" : { "type" : "keyword" }, "OriginCityName" : { "type" : "keyword" }, "OriginCountry" : { "type" : "keyword" }, "OriginLocation" : { "type" : "geo_point" }, "OriginRegion" : { "type" : "keyword" }, "OriginWeather" : { "type" : "keyword" }, "dayOfWeek" : { "type" : "integer" }, "timestamp" : { "type" : "date" } } } j
常用的filed-datatype 类型(filed-datatype):filed-datatype 一般是ES存储数据类型,主要针对的是mapping的数据
字符串类型:text,keyword。
text:文本类型,在索引文件中,存储的不是原字符串,而是使用分词器对内容进行分词处理后得到一系列的词根,然后一一存储在index的倒排索引中。
keyword:关键字类型,将原始输入内容当成一个词根存储在倒排索引中,与text字段的区别是该字段不会使用分词器进行分词。
在搜索中如果想使用分词就使用text类型的字符串,如果想精确查找就使用keyword字符串。如果即想分词查找又想精确查找。就使用多字段,外围字段使用text分词查找,内部使用keyword(反过来也可以)
1 2 3 4 5 6 7 8 9 "firstname" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }
数字类型:long、integer、short、byte、double、float、half_float、scaled_float。
long、integer、short、byte、double、float这些字段的取值与java一致,毕竟ES底层也是Java写的。
half_float : 浮点数,但只是用16位
scaled_float :底层基于long存储,支持一个固定的精度因子。如果存储浮点数0.15,如果设置scaling_fac-tor=100,则该类型会以一个整数15进行存储,有效提高其存储性能。
日期类型(date):json对象没有日期类型,故java中的日期数据会被格式化。
字符串类型,例如”2015-01-01”
数字类型(long),表示从1970-01-01以来的毫秒数
int类型,表示从1970-01-01以来的秒数
布尔类型(boolean):存储布尔值,true和false。
二进制(binary):该类型可以用来存储二进制数据,存储之前,需要先用Base64进行编码码。该字段类型默认不存储在索引中(store=fa-sle,但该值还是会存储在_source字段中-),默认也是不能用来当搜索条件。
数组类型(array):存储数组信息。可以字符类型,也可以是数字类型。
对象类型(object):存储对象或json对象字符串。(主要是存储json字符串)
嵌套类型(nested):存储是对象用于关联查询。
object和nested类型主要是区别是object主要是存储,不能做为关联查询。但是nested在嵌套对象中进行关联查询,在嵌套对象中创建; 倒排索引。
地理信息类型(Geo):geo_point、geo_shape datatype
地图坐标(geo_point):存储经纬度。其使用场景:
Geo Bounding Box Query 找出落在指定矩形框中的坐标点
Geo Distance Query 找出与指定位置在给定距离内的点
找出与指定点距离在给定最小距离和最大)距离之间的点
Geo Polygon Query 查找包含在多边形范围内的文档 与地理位置相关的查询。
地理形状(geo_shape):数据类型方便了对任意地理形状(如矩形和多边形)进行索引和搜索。当正在索引的数据或正在执行的查询包含除了点以外的形状时应该使用它。
geo相关的类型主要是存储地理信息和地理信息计算。这种数据存储可以在LBS(电子围栏系统)使用,我们常用打车软件中计算点到点位置信息和展示地理位置信息都可以使用ES进行底层数据处理。redis也支持地理信息也可以使用作为计算
查看索引详细信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 GET bank { "bank" : { "aliases" : { }, "mappings" : { "properties" : { "account_number" : { "type" : "long" }, "address" : { "type" : "text" , "fields" : { "keyword" : "type" : "keyword" , "ignore_above" : 256 } } }, "age" : { "type" : "long" }, "balance" : { "type" : "long" }, "city" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "email" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "employer" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "firstname" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "gender" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "lastname" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } }, "state" : { "type" : "text" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } } } }, "settings" : { "index" : { "creation_date" : "1663750625000" , "number_of_shards" : "1" , "number_of_replicas" : "0" , "uuid" : "wC0eRZocScGU9n2OxEV6uA" , "version" : { "created" : "7060099" }, "provided_name" : "bank" } } } }
倒排索引 正排索引 :(index)正排表是以文档的ID为key,表中记录文档中每个关键字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。也就是普通索引
item就是具体的数据,keyword就是对应的字段和关键字,根据item信息去查询全部具体数据,这种更像是字典或者书籍的目录,也就是从这种就是正排索引
倒排索引 :(Inverted index)也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,它是文档检索系统中最常用的数据结构。
倒排索引更像书中的索引页,根据对应的keyword去查询具体的数据,一个keyword可能会在多个item中。
ElasticSearch的高可用与扩展 ElasticSearch是一个分布式、可扩展、近实时的搜索和数据分析系统系统,上面解释关于名称索引还有倒排索引,这部分解释一些关于ES集群的一些名称和配置。一般正常在生成环境中部署的都是ElasticSearch的集群,一般集群就意味着高可用和可扩展(否则用单体会是更好的选择)
集群(cluster) ES的集群搭建很简单,不需要依赖第三方协调管理组件,自身内部就实现了集群的管理功能。ES集群由一个或多个Elasticsearch节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 my-application。确保不同的环境中使用不同的集群名称,否则最终会导致节点加入错误的集群。
elasticsearch.yml 中Cluster的配置
1 2 3 4 5 6 7 cluster.name: cluster
Node可以理解为启动的ElasticSearch的单个实例。节点通过 node.name 来设置节点名称,如果不设置则在启动时给节点分配一个随机通用唯一标识符作为名称。ElasticSearch的自动发现机制,当配置相同的cluster.name会被加入相同的集群。
1 2 3 4 5 6 7 8 9 10 11 12 node.name: node-1 node.master: true node.data: true
在节点可以指定节点属性,候选主节点和数据节点。通过node.master指定候选主节点,通过node.data指定是否为数据节点。默认都为true。
数据节点 : 负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(data节点)对机器配置要求比较高,对CPU、内存和I/O的消耗很大。通常随着集群的扩大,需要增加更多的数据节点来提高性能和可用性。
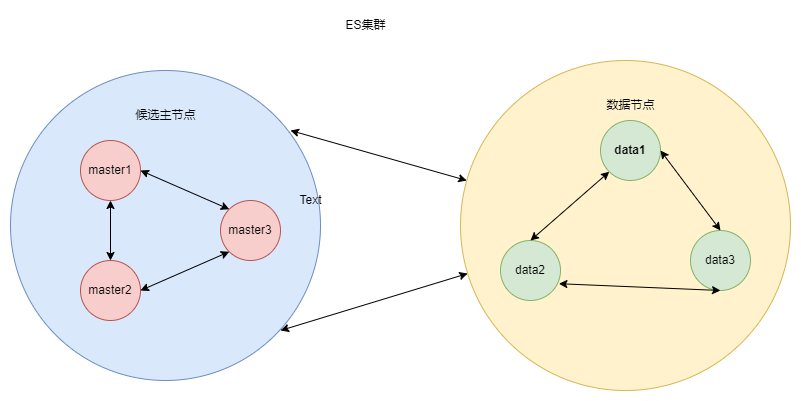
候选主节点 :可以被选举为主节点(master节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。
协调节点 :负责分发请求、收集结果等操作,而不需要主节点转发。虽然对节点做了角色区分,但是用户的请求可以发往任何一个节点。协调节点是不需要指定和配置的,集群中的任何节点都可以充当协调节点的角色。(协调节点也有被称为客户端节点)
一个节点既可以是候选主节点也可以是数据节点,但是由于数据节点对CPU、内存核I/0消耗都很大,所以如果某个节点既是数据节点又是主节点,那么可能会对主节点产生影响从而对整个集群的状态产生影响。
因此为了提高集群的健康性,我们应该对Elasticsearch集群中的节点做好角色上的划分和隔离。可以使用几个配置较低的机器群作为候选主节点群。主节点和其他节点之间通过Ping的方式互检查,主节点负责Ping所有其他节点,判断是否有节点已经挂掉。其他节点也通过Ping的方式判断主节点是否处于可用状态。
如果由于网络或其他原因导致集群中选举出多个Master节点,使得数据更新时出现不一致,这种现象称之为集群脑裂(Cluster Split Brain)。 集群中的一些节点认为其他节点已经下线,并开始独立地运行,而不是作为集群中的一个整体运行,导致集群的不可用。
脑裂 可能由以下几个原因造成:
网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片
节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
内存回收:主节点的角色既为master又为data,当data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
为了避免脑裂现象的发生,我们可以从原因着手通过以下几个方面来做出优化措施:
适当调大响应时间,减少误判。通过参数discovery.zen.ping_timeout设置节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如6s,discovery.zen.ping_timeout:6),可适当减少误判。
选举触发,在候选集群中的节点的配置文件中设置参数discovery.zen.munimum_master_nodes的值,这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是1,官方建议取值(master_eligibel_nodes/2) + 1,其中master_eligibel_nodes为候选主节点的个数。这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于discovery.zen.munimum_master_nodes个候选节点存活,选举工作就能正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
角色分离,候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点“已死”的误判。
分片(shards) 当索引上的数据量太大的时候,ES通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个 分片 。
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,所以在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。
使用分片可以,水平分割/缩放内容,提高扩展能力。在分片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量。
分片的数量和下面介绍的副本数量都是可以通过创建索引时的settings来配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 GET myIndex/_settings { "myIndex" : { "settings" : { "index" : { "creation_date" : "1663750625000" , "number_of_shards" : "1" , "number_of_replicas" : "0" , "uuid" : "wC0eRZocScGU9n2OxEV6uA" , "version" : { "created" : "7060099" }, "provided_name" : "myIndex" } } } } PUT /myIndex { "settings" : { "number_of_shards" : 5 , "number_of_replicas" : 1 } }
查看分片信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 GET _cat/shards?v index shard prirep state docs store ip node read_me 0 p STARTED 1 4.4kb 10.0.12.5 node-1 kibana_sample_data_ecommerce 0 p STARTED 4675 4.9mb 10.0.12.5 node-1 .kibana_task_manager_1 0 p STARTED 2 21.6kb 10.0.12.5 node-1 test 0 p STARTED 1 3.7kb 10.0.12.5 node-1 .kibana_1 0 p STARTED 1 4kb 10.0.12.5 node-1 bank 0 p STARTED 1000 414.8kb 10.0.12.5 node-1 products 0 p STARTED 3 4.3kb 10.0.12.5 node-1 products 0 r UNASSIGNED kibana_sample_data_logs 0 p STARTED 14074 11.2mb 10.0.12.5 node-1 .tasks 0 p STARTED 1 6.3kb 10.0.12.5 node-1 .security-7 0 p STARTED 42 76.9kb 10.0.12.5 node-1 .apm-agent-configuration 0 p STARTED 0 283b 10.0.12.5 node-1 kibana_sample_data_flights 0 p STARTED 13059 6.4mb 10.0.12.5 node-1 .kibana_2 0 p STARTED 203 1.1mb 10.0.12.5 node-1 index:索引名称 shard:分片数 prirep:分片类型,p=pri=primary为主分片,r=rep=replicas为复制分片 state:分片状态 STARTED为正常分片,INITIALIZING为异常分片 docs:记录数 store:存储大小 ip:es节点ip node:es节点名称
副本(replica) 副本是分片的复制。如果分片/节点出现故障,副本可以提供数据的查询等操作,提供高可用性,并且通过对所有副本并行执行搜索,扩展搜索量/吞吐量。每个主分片都有一个或多个副本分片。主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 n -1(其中n为节点数)。
默认情默认情况下,ElasticSearch中的每个索引都分配了5个主分片和1个副本况下,ElasticSearch中的每个索引都分配了5个主分片和1个副本。创建索引后,您可以随时动态更改副本数,但不能更改主分片数。
文档的新建、索引和删除请求都是写操作。这些操作都是先在主分片中存储,然后在并发的同步给其他分片,在并发同步数据的过程中为了保证数据的准确性,ES引入乐观锁。ES在每次同步的数据中增加版本号_version,在数据被修改后版本递增,当所有副本都同步完之后在通知协调节点,操作成功,然后协调节点在向客户端同步操作成功数据。
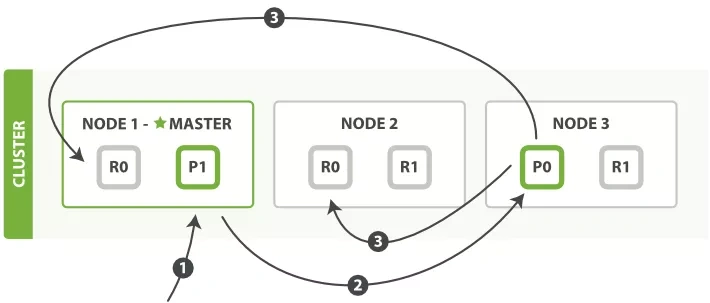
node1 为协调节点,P0和P1是主分片,R0和R1副本。
1、customer向node1提交P0分片的写数据。
2、node1节点作为协调节点,向P0分片的节点发送处理数据,node3节点将P0的数据保存到主分片。
3、node3节点保存完主分片数据,向node2节点和node1节点的R0副本并发同步数据。
最后通知给node1节点操作完成,然后告知customer
总结
将数据分片是为了提高可处理数据的容量和易于进行水平扩展,为分片做副本是为了提高集群的稳定性和提高并发量。
副本是乘法,越多消耗越大,但也越保险。分片是除法,分片越多,单分片数据就越少也越分散。
副本越多,集群的可用性就越高,但是由于每个分片都相当于一个Lucene的索引文件,会占用一定的文件句柄、内存及CPU,并且分片间的数据同步也会占用一定的网络带宽,所以索引的分片数和副本数也不是越多越好
ElasticSearch的搜索方式 URI API Search 搜索movies索引中,对tile字段查询2012,排序字段是year倒排,分页从0到10第一页,查询超时时间是1s。
1 GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
q 指定查询语句,使用 query string syntax
df 默认字段,不指定是会对所有字段进行查询
sort 排序 / from 和 size 用于分页
profile 可以查看查询是如何被执行的
DSL Search API 查询kibana_sample_data_ecommerce 索引全部数据,根据order_date时间倒序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET kibana_sample_data_ecommerce/_search { "sort" : [ { "order_date" : { "order" : "desc" } } ], "query" : { "match_all" : { } } }
在实际生成当中使用DSL Search API的时候更多,因为DSL支持的语法和优化更多,而是可以通过
ES的搜索查询类型 词项查询(Term queries) Term (词项/条):term是表达语义最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理term。
ES 中 对term 查询对输入不做分词,会将输入作为整体,在倒排索引中查找准确的词项,并且使用相关度算分公式每个包含该词项的文档进行算分,返回的文档会根据算分结果进行排序一般相关度高的会排在前面。注意,由于term查询是不做分词,一般使用的filed-datatype是keyword,而不是text类型,text在存储的时候会进行分词,在使用term的等值查询的时候查询不到数据。
Term Level Query :Term Query(词项等值查询) 、Range Query(词项的范围查找)、Exists Query(词项的存在查找)、Perfix Query(词项的前缀查找)、WildCard Query(词项的通配符查找,WildCard 扑克牌的万能牌)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 GET /kibana_sample_data_flights/_search { "query" :{ "term" :{ "DestCountry" :{ "value" :"CH" } } } } GET /kibana_sample_data_flights/_search { "query" :{ "term" :{ "DestCountry" :"CH" } } } GET kibana_sample_data_flights/_search { "query" : { "constant_score" : { "filter" : { "range" : { "AvgTicketPrice" : { "gte" : 500 , "lte" : 1000 } } } } } } GET /kibana_sample_data_flights/_search { "query" : { "exists" : { "field" : "DestCountry" } } } GET /kibana_sample_data_flights/_search { "query" : { "prefix" : { "DestCountry" : "C" } } } GET /kibana_sample_data_flights/_search { "query" : { "wildcard" : { "FlightNum" : { "value" : "1*1" , "boost" : 1.0 , "rewrite" : "constant_score" } } } }
全文本查询(Full text queries) 分词匹配搜索:通常用于搜索文本字段,需要用户提供关键字来完成。搜索时候会进行分词,查询字符串会先传递给一个分词器进行分词。然后生成一个提供查询的词项列表。然后每个词项逐个的进行底层查询,最终将结果进行合并,并为每个文档进行算分,最后根据算分结果给出排序。例如查询matrix reloaded 会查询包括 matrix和reload的所有结果。
总结一下就是这个查询分两步。首先是分词,通过分词器将查询的关键词分词(这个可以手动指定也可以自动指定)。然后将分词好的term(词项)列表去通过term查询查找(底层还是term查找),然后算分排序返回。全文本搜索一般使用text类型的字段,因为text类型的字段在存储过程中就已经被分词,这里推荐在创建索引和查询时使用同样的分词器。因为分词的使用可能会有不同的偏差导致查询不到具体数据。
常见的ES中的分词器有standard、simple、pattern、keyword、english;中文的分词器有ik_smart、ik_max_word、icu_analyzer默认ES中时没有中文分词器中文的分词器需要自己在插件中安装。安装方法自己去Google吧
使用分词器分词示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 GET _analyze { "analyzer" : "standard" , "text" : ["2 bird flying in the sky " ] } GET _analyze { "analyzer" : "simple" , "text" : ["2 bird flying in the sky " ] } GET _analyze { "analyzer" : "keyword" , "text" : ["2 running Quick brown-foxes leap over lazy dogs in the summmer evening " ] } GET _analyze { "analyzer" : "pattern" , "text" : ["2 running Quick brown-foxes leap over lazy dogs in the summmer evening " ] } GET _analyze { "analyzer" : "english" , "text" : ["2 running Quick brown-foxes leap over lazy dogs in the summmer evening " ] } GET _analyze { "analyzer" : "icu_analyzer" , "text" : ["他说的确实在理" ] } GET _analyze { "analyzer" : "ik_smart" , "text" : ["他说的确实在理" ] } GET _analyze { "analyzer" : "ik_max_word" , "text" : ["他说的确实在理" ] }
Macth Query Level :Match Query (分词匹配查询)/ Match Phrase Query(分词短语匹配查询)/ Query String Query(字符串查询)/ Multi Match Query(多字段分词匹配查询)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 GET kibana_sample_data_ecommerce/_search { "query" : { "match" : { "customer_full_name" : "Eddie Underwood" } } } GET kibana_sample_data_ecommerce/_search { "query" : { "match" : { "customer_full_name" : { "query" : "Eddie Underwood" , "operator" : "and" } } } } GET kibana_sample_data_ecommerce/_search { "query" : { "match_phrase" : { "customer_full_name" : { "query" : "Eddie Underwood" } } } } GET kibana_sample_data_ecommerce/_search { "query" : { "query_string" : { "query" : "(Clothing) OR (Shoes)" , "default_field" : "category" } } } GET kibana_sample_data_ecommerce/_search { "query" : { "multi_match" : { "query" : "King" , "fields" : ["category" ,"customer_full_name" ] } } }
复合查询(Compound queries ) 复合查询 :复合查询就是将一些简单的查询组合在一起作为查询条件进行文档检索。
相关性算分 (Relevance Score):搜索的相关性算分,是描述一个文档和查询语句的匹配程度,ES会对每个匹配的查询条件的结果进行算分_score,算分的本质是ES会把返回结果根据算分的高低进行排序,一般排在最前面的都是相关性高的。ES5.0之前使用的是TF-IDF算法进行算分,后面的版本优化使用BM25(Best Match)算法进行算分。
使用explain可以查看ES算分过程,这个和MySQL看执行计划是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 GET kibana_sample_data_ecommerce/_search { "explain" : true , "query" : { "match_phrase" : { "customer_full_name" : { "query" : "Eddie Underwood" } } } } { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 1 , "successful" : 1 , "skipped" : 0 , "failed" : 0 }, "hits" : { "total" : { "value" : 1 , "relation" : "eq" }, "max_score" : 8.399749 , "hits" : [ { "_shard" : "[kibana_sample_data_ecommerce][0]" , "_node" : "vj8gacmkRCS9gh9d9tassw" , "_index" : "kibana_sample_data_ecommerce" , "_type" : "_doc" , "_id" : "FHbQXoMB7xzzV5IgPJqV" , "_score" : 8.399749 , "_source" : { "category" : [ "Men's Clothing" ], "currency" : "EUR" , "customer_first_name" : "Eddie" , "customer_full_name" : "Eddie Underwood" , "customer_gender" : "MALE" , "customer_id" : 38 , "customer_last_name" : "Underwood" , "customer_phone" : "" , "day_of_week" : "Monday" , "day_of_week_i" : 0 , "email" : "[email protected] " , "manufacturer" : [ "Elitelligence" , "Oceanavigations" ], "order_date" : "2022-10-03T09:28:48+00:00" , "order_id" : 584677 , "products" : [ { "base_price" : 11.99 , "discount_percentage" : 0 , "quantity" : 1 , "manufacturer" : "Elitelligence" , "tax_amount" : 0 , "product_id" : 6283 , "category" : "Men's Clothing" , "sku" : "ZO0549605496" , "taxless_price" : 11.99 , "unit_discount_amount" : 0 , "min_price" : 6.35 , "_id" : "sold_product_584677_6283" , "discount_amount" : 0 , "created_on" : "2016-12-26T09:28:48+00:00" , "product_name" : "Basic T-shirt - dark blue/white" , "price" : 11.99 , "taxful_price" : 11.99 , "base_unit_price" : 11.99 }, { "base_price" : 24.99 , "discount_percentage" : 0 , "quantity" : 1 , "manufacturer" : "Oceanavigations" , "tax_amount" : 0 , "product_id" : 19400 , "category" : "Men's Clothing" , "sku" : "ZO0299602996" , "taxless_price" : 24.99 , "unit_discount_amount" : 0 , "min_price" : 11.75 , "_id" : "sold_product_584677_19400" , "discount_amount" : 0 , "created_on" : "2016-12-26T09:28:48+00:00" , "product_name" : "Sweatshirt - grey multicolor" , "price" : 24.99 , "taxful_price" : 24.99 , "base_unit_price" : 24.99 } ], "sku" : [ "ZO0549605496" , "ZO0299602996" ], "taxful_total_price" : 36.98 , "taxless_total_price" : 36.98 , "total_quantity" : 2 , "total_unique_products" : 2 , "type" : "order" , "user" : "eddie" , "geoip" : { "country_iso_code" : "EG" , "location" : { "lon" : 31.3 , "lat" : 30.1 }, "region_name" : "Cairo Governorate" , "continent_name" : "Africa" , "city_name" : "Cairo" } }, "_explanation" : { "value" : 8.399749 , "description" : "" "weight(customer_full_name:" eddie underwood" in 0) [PerFieldSimilarity], result of:" "" , "details" : [ { "value" : 8.399749 , "description" : "score(freq=1.0), computed as boost * idf * tf from:" , "details" : [ { "value" : 2.2 , "description" : "boost" , "details" : [ ] }, { "value" : 8.204263 , "description" : "idf, sum of:" , "details" : [ { "value" : 3.8400407 , "description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:" , "details" : [ { "value" : 100 , "description" : "n, number of documents containing term" , "details" : [ ] }, { "value" : 4675 , "description" : "N, total number of documents with field" , "details" : [ ] } ] }, { "value" : 4.364222 , "description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:" , "details" : [ { "value" : 59 , "description" : "n, number of documents containing term" , "details" : [ ] }, { "value" : 4675 , "description" : "N, total number of documents with field" , "details" : [ ] } ] } ] }, { "value" : 0.46537602 , "description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:" , "details" : [ { "value" : 1.0 , "description" : "phraseFreq=1.0" , "details" : [ ] }, { "value" : 1.2 , "description" : "k1, term saturation parameter" , "details" : [ ] }, { "value" : 0.75 , "description" : "b, length normalization parameter" , "details" : [ ] }, { "value" : 2.0 , "description" : "dl, length of field" , "details" : [ ] }, { "value" : 2.1206417 , "description" : "avgdl, average length of field" , "details" : [ ] } ] } ] } ] } } ] } }
Query Context (查询上下文):Query Context主要包含的一些查询语句信息。他们主要反应文档匹配程度。除了内容匹配之外还有匹配文档相关性算分,返回结果会根据相关性算分排序
Filter Context (过滤器上下文):Filter Context也是包含一些查询语句。他主要反应的是文档是否匹配,没有匹配程度的概念,即查询出文档不需要相关性算分。Filter 可以利用缓存获得更好的性能
简单总结一下就是query context 内的查询子语句都是需要算分的,而filter context 的查询子语句不需要算分。当多个查询子语句复合使用的收就可以通过那些设置成功query 那些设置成filter来提高查询性能,不是所有查询字段都需要相关性算分。
bool查询 bool查询:默认的复合查询,包含一个简单或者多个简单查询。可以使用must、must_not、should、filter表示简单查询之间的逻辑。
must:文档必须要匹配must下的查询条件,参与算分。should:文档可以匹配也可以不匹配should下的查询条件,匹配的文档算分会更高must_not:匹配该选项下的查询条件的文档会被过滤,不会返回。filter:和must类似,不同的是filter中的条件不会参与算分。
相关性算分不仅仅适用于全文本搜索。也适合返回yes|on的子语句的复合查询,匹配的子语句越多,相关性算分越高。must和should都会算分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 GET kibana_sample_data_ecommerce/_search { "query" : { "bool" : { "must" : [ { "term" : { "currency" : { "value" : "EUR" } } }, { "match" : { "customer_full_name" : "Underwood" } } ], "must_not" : [ { "term" : { "day_of_week" : { "value" : "Monday" } } }, { "match" : { "category" : "shoes" } } ], "should" : [ { "terms" : { "sku" : [ "ZO0299602996" , "ZO0549605496" , "ZO0489604896" , "ZO0185501855" ] } }, { "range" : { "products.taxless_price" : { "gte" : 10 , "lte" : 200 } } } ], "filter" : { "range" : { "order_date" : { "gte" : "2010-01-01" , "lte" : "2022-10-10" } } } } } }
constant score 查询 constant score 查询:检索可以包装一个其它类型的查询,并返回匹配过滤器中的查询条件且具备相同评分的文档。评分的数值默认是1.0,也可以使用boost参数。使用constant score 查询可以避免TF-IDF算分,部分提高效率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET kibana_sample_data_flights/_search { "query" : { "constant_score" : { "filter" : { "term" : { "FlightDelay" : false } } , "boost" : 1.5 } } }
boosting 查询 boosting查询:适用于需要对评分进行调整的场景,它会把多个查询封装在一起并调整其中一个查询条件的评分,但是不会把记录从返回结果中删除。positive用于提升相关性算分权重,negative用于降低相关性算分权重。negative_boost表示降低相关性权重的数值,一般在0到1之间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 GET kibana_sample_data_flights/_search { "query" : { "boosting" : { "positive" : { "match" : { "DestCountry" : "CH" } }, "negative" : { "match" : { "DestCountry" : "ES" } }, "negative_boost" : 0.2 } } }
也可以使用复合查询中的boost参数的值,调整相关性参数。boost>1相关度算分权重提升,0<boost<1打分的相关度算分权重相对下降是原来的0到1倍之间,boost<0表示相关度算分权重为负分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 GET kibana_sample_data_ecommerce/_search { "query" : { "bool" : { "should" : [ { "match" : { "category" : { "query" : "Men's Clothing" , "boost" :1.5 } } }, { "match" : { "category" : { "query" : "Women's Clothing" , "boost" : 0.2 } } } ] } } }
ES数据搜索的简单优化 相关性算分搜索的优化
ES 使用term查询会有score 分数。一般会根据score分数来给出相关的查询关联度,关联度越高的,结果越靠前。将Query 转成filter,会忽略TF-IDF计算,避免相关性计算的开销(score 分数都是 0.0),filter 可以有效利用缓存。或者使用constant_score使所有等分都等1.0不进行计算。(使用constant_score和filter也算是复合搜索)
一般使用term查找的基本上都是等值查找和MySQL中的查找类似,把数据返回就可以了,然后可以通过排序字段进行手动排序,没有必要进行得分排序。不过如果你有需要可以使用score关联程度,那就把filter或者constant_score去掉就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 GET kibana_sample_data_flights/_search { "query" : { "constant_score" : { "filter" : { "term" : { "FlightDelay" : false } } } } } GET /kibana_sample_data_flights/_search { "query" : { "bool" : { "filter" : { "term" : { "FlightDelay" : false } } } } }
优化查询中包含不是相等的问题
ES在查询中一般都是包含,特别是在一个字段存储时是数组的数据类型,导致你只想查询其中的一个值,结果查询出来多个结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 GET kibana_sample_data_ecommerce/_search { "query" : { "constant_score" : { "filter" : { "term" : { "manufacturer.keyword" : "Oceanavigations" } } } } } { "_index" : "kibana_sample_data_ecommerce" , "_type" : "_doc" , "_id" : "FHbQXoMB7xzzV5IgPJqV" , "_score" : 1.0 , "_source" : { "category" : [ "Men's Clothing" ], "currency" : "EUR" , "customer_first_name" : "Eddie" , "customer_full_name" : "Eddie Underwood" , "customer_gender" : "MALE" , "customer_id" : 38 , "customer_last_name" : "Underwood" , "customer_phone" : "" , "day_of_week" : "Monday" , "day_of_week_i" : 0 , "email" : "[email protected] " , "manufacturer" : [ "Elitelligence" , "Oceanavigations" ], "order_date" : "2022-10-03T09:28:48+00:00" , "order_id" : 584677 , } }
解决这种问题,可以通过增加 manufacturer_count字段,增加 manufacturer_count在查询时候带上查询条件 manufacturer_count =1就可以解决。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 GET kibana_sample_data_ecommerce/_search { "query" : { "bool" : { "must" : [ { "term" : { "manufacturer.keyword" : "Oceanavigations" } }, { "term" : { "manufacturer_count" : 1 } } ] } } }
或者使用must_not去做排除,但是这种要把对应的枚举都做出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 GET kibana_sample_data_ecommerce/_search { "query" : { "bool" : { "must" : [ { "term" : { "manufacturer.keyword" : "Oceanavigations" } } ], "must_not" : [ { "terms" : { "manufacturer.keyword" : [ "Low Tide Media" , "Elitelligence" , "Primemaster" , "Pyramidustries" , "Tigress Enterprises" , "Pyramidustries active" , "Angeldale" , "Microlutions" ] } } ] } } }
这种优化一般根据业务去优化,如果你的数据是可以枚举的推荐使用must_not因为这种不用修改索引字段,但是如果数组中的数据不可以枚举,那就选择count也是一个不错的选择,不过这种要重建索引。
ES搜索分页优化
在ES查询中默认是可以使用分页的,就像MySQL中分页使用offset 和limit,在ES中使用from和size这两个参数。
1 2 3 4 5 6 7 8 9 10 11 GET kibana_sample_data_flights/_search { "query" : { "match" : { "DestCountry" : "CH" } }, "from" : 0 , "size" : 5 }
不过这种使用方法,会有限制就是from+size 默认不能超过10000。可以通过修改索引参数index.max_result_window调整,但是这种方式在查询后会出现慢查询。
from + sizede 查询过程:协调节点将查询请求发送给所有分片,各分片收到请求后,查出 from + size 的数据,并返回给协调节点。例如:当前请求是查询第5~10笔数据,from + size = 10,因此每个分片都要返回排序后的前10笔数据,协调节点将收到的数据进行合并,重新排序,然后返回指定的size分页数据给客户端。
深分页的情况下,也就是from + size 值特别大,可能会造成慢查询。因为每个节点都需要返回 from + size 的排序数据,然后最终还需要合并以及排序,就算没有内存溢出,对CPU和IO也有巨大影响。
所以实现简单,适用于少量数据,数据量不超过10w,适合浅分页。当深度分页时性能较差
可以使用ES的search_after和去优化
search_after 在排序的基础上,基于上一笔的sort值,查询排在它之后的数据,以此来实现分页。search_after 是无状态的,它总是查询ES索引最新的数据,这一点跟 scroll 查询完全相反。(scroll 维护成本高,而且scroll_id 存在缓存时间,对于实时性也会有影响,所以后面不推荐使用)
不过使用时search_after一定要带排序参数,而且他的排序参数至少要两个,否则就会报错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 GET kibana_sample_data_ecommerce/_search { "query": { "bool": { "must": [ { "match": { "category": { "query": "Men's Clothing", "boost":1.5 } } } ] } }, "sort": [ { "order_id": { "order": "asc" }, "order_date": { "order": "asc" } } ], //在排序order_id字段584677后分页2000000 "search_after":["584677",2000000] }
排序字段大于两个报错信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 { "error" : { "root_cause" : [ { "type" : "illegal_argument_exception" , "reason" : "search_after has 2 value(s) but sort has 3." } ], "type" : "search_phase_execution_exception" , "reason" : "all shards failed" , "phase" : "query" , "grouped" : true , "failed_shards" : [ { "shard" : 0 , "index" : "kibana_sample_data_ecommerce" , "node" : "vj8gacmkRCS9gh9d9tassw" , "reason" : { "type" : "illegal_argument_exception" , "reason" : "search_after has 2 value(s) but sort has 3." } } ], "caused_by" : { "type" : "illegal_argument_exception" , "reason" : "search_after has 2 value(s) but sort has 3." , "caused_by" : { "type" : "illegal_argument_exception" , "reason" : "search_after has 2 value(s) but sort has 3." } } }, "status" : 400 }
这种分页做法时可以,但是不支持随便跳转页面,就像微博或者淘宝一直往下下拉分页,这种就可以避免随便跳页。
总结 写了关于这么多关于ES的内容,其实本质还是想把自己使用ES的过程记录下来,在接触ES这段时间发现,通过ES的使用可以提高查询效率,而且在做一下数据库上的统计信息计算,也可以通过ES的聚合实现。不用每次都写SQL计算,当数量大的时候,统计也是很耗时的。
还有就是通过ES可以做数据的聚合,即把原来几张表的数据,通过ES做成一个宽表这样在一些数据搜索时候额外的方便,不需要做跨表甚至跨库的查询。
在一个就是使用中ES的实时性的问题,这种可以通过canal去做binlog实时监听,将binlog信息转化成MQ消息同步给ES,可以做到秒级的实时笑果。这个地方肯定有人会问,为啥不canal直接同步ES数据,因为binlog本身有很多数据不一定需要处理(特别是在修改表结构产生大量不需要的同步数据),在同步过程中可能出现数据的聚合和调整,所以增加kafka消费时的在处理数据的时候增加中间层,可以做业务上的处理。
最后上面讲的也都是关于ES一些查询上的简单技巧,后续包括ES操作推荐使用elasticsearch-rest-high-level-client,这个就是一些API上的使用,可以简化我们代码上的处理。本文涉及到的所有的ES执行的DSL语句都是通过kibana执行的。
杂记 TF-IDF算法:term frequency–inverse document frequency 是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
词频(Term Frequency):某个词在文章中出现的频率。公式 词频 = 某个词出现的次数/整篇文章的总的词数
逆文档频率(inverse document frequency):log(总文档数/存在该词的文档数+1)
TF-IDF = TF*IDF
例如小米手机就会被分词 小米 + 手机 小米手机的TF-IDF = 小米TF * 小米IDF + 手机TF * 手机 IDF。